平台
Windows/Ubuntu系统
科大讯飞开发套件iFLYOSMT8516开发套件
讯飞开发平台
python
开发套件iFLYOS MT8516
MT8516开发套件是一款基于MTK平台MT8516处理器和科大讯飞环形 6麦阵列结构的语音整体解决方案。此外还提供红外、串口、ZigBee等多种接口,小巧易扩展,搭载iFLYOS生态,提供海量内容服务与定制化接口,满足多种远、近场语音交互场景。
硬件系统
硬件构成和产品


整个开发套件分为三部分,最上面一层为功能按键和LED灯板,主要提供MIC禁音键、播放/暂停键、音量键及LED灯效。中间一层为核心开发板,主要包括一个MT8516A芯片和环形6颗麦克风阵列。最下面一层主要包括一个扬声器、配网按键和电源接口(Type-C)。
核心板——MT8516A
MT8516是联发科技在2017年5月推出的一款面向智能语音助手设备和智能音响的系统单芯片。支持多达8个TDM通道和2个PDM输入,以支持来自多个源的音频输入,适用于远场麦克风语音控制和智能音响设备。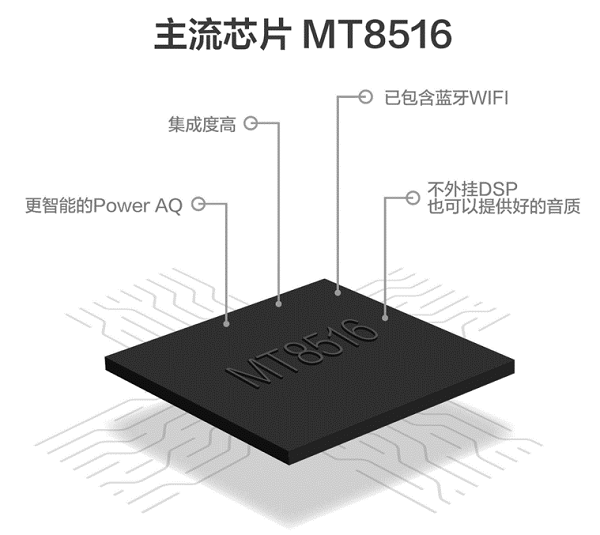

其系统设计框图为: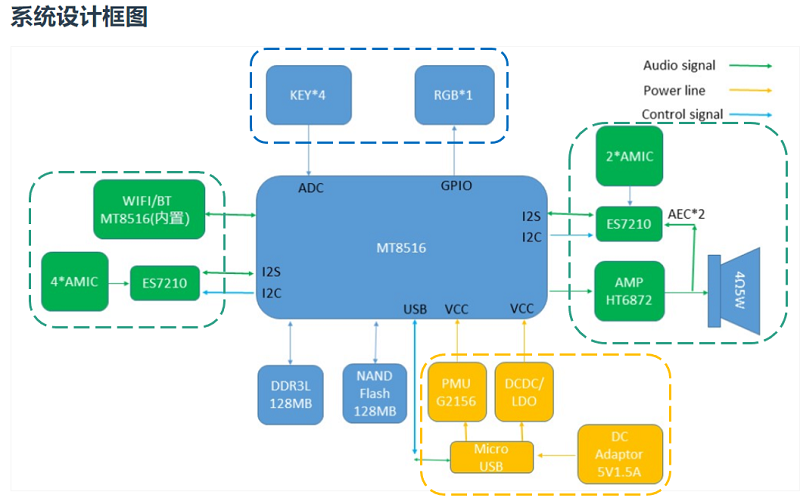
蓝色部分为按键和LED灯模块。绿色部分为外设模块,主要包括6个麦克风和1个扬声器。其中AMIC为麦克风,4Ω5W为扬声器。黄色部分为电源模块。
最下角的2个模块分别为外置128/256MB DDR3和外置128/256MB FLASH内存。
麦克风——环形6颗麦克风阵列

产品特性:
- 远/近场拾音
方案前端采用科大讯飞6麦克风阵列,能够实现家居场景5-10m左右的用户指令音频拾取,通过新一代神 经网络降噪算法对拾取音频进行处理,提供高品质降噪后音频给到后端,以保障唤醒、识别效果。 - 噪声抑制
该功能基于科大讯飞6麦克风阵列中的声源定位和波束增强等算法特性,通过采集指令声源(控制设备 的发音人)所在波束范围内的声音,抑制或者不处理其它波束所接收的声音,以提升采集声音的效果,为后续唤醒和命令词识别效果提供保障。 - 回声消除
支持用户交互过程中,实现一次唤醒,多轮交互的控制方式,即用户可以中断播报进程进行下一轮交互,让交互更加自然,流畅。
软件系统
快速使用
- 下载小飞在线
APP并登录,下载地址。 - 长按设备配网键
5秒,听到语音和黄色呼吸灯提示后松手,进入配网模式。 - 在小飞在线
APP点击添加设备,点击连接。(需要打开蓝牙、网络和定位)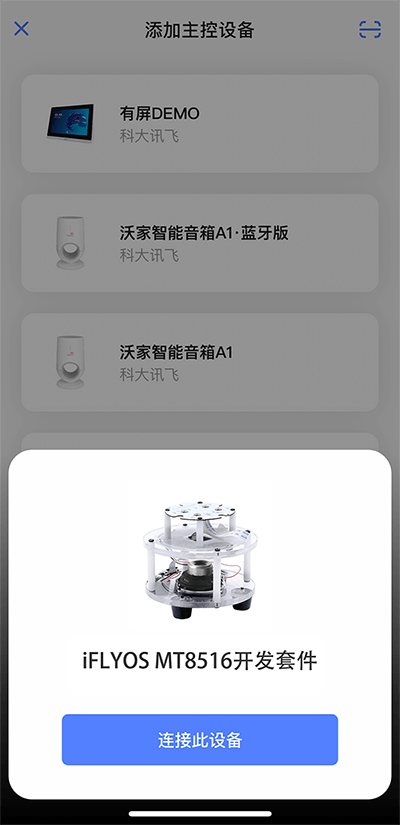
- 输入网络账号密码,等待设备联网即可。
- 完成设备联网后,可以说
蓝小飞,***进行语音交互。
二次开发
环境搭建
下载MTK8516交叉编译工具链
解压缩工具链,如果系统没有7z,请先安装,安装方式:1
sudo apt-get install p7zip
解压:1
7z x yocto_toolchain_7.3.7z
安装:1
chmod +x oecore-x86_64-aarch64-toolchain-nodistro.0.sh
1 | ./oecore-x86_64-aarch64-toolchain-nodistro.0.sh |
推荐安装目录为:/etc/iflyosBoards/mtk8516,等待安装完成。
设置环境变量:1
source /etc/iflyosBoards/mtk8516/environment-setup-aarch64-poky-linux
安装第三方库:地址
复制到安装目录下的sysroot目录:1
mv /***/lib/* /etc/iflyosBoards/mtk8516/sysroots/aarch64-poky-linux/usr/lib/
1 | mv /***/lib64/* /etc/iflyosBoards/mtk8516/sysroots/aarch64-poky-linux/usr/lib64/ |
下载开源工程项目
MTK8516开发套件已经内置了工程项目,可以不用下载,但如果想在电脑上看看也可以下载到本地。
解压后目录如下:1
2
3build_mt8516.sh
jsruntime
smartSpeakerApp
编译1
source build_mt8516.sh
目标文件目录: /etc/iflyosBoards/mtk8516-edu/install1
2
3
4
5
6
7/etc/iflyosBoards/mt8516-edu/install
├── bin
│ └── iotjs #jsruntime可执行程序
├── iFLYOS.json #主程序启动配置文件
├── lib
│ └── libiotjs.so #jsruntime库
├── smartSpeakerApp #js应用层文件目录
部署
MTK8516开发套件本质上是一个Liunx系统,可以使用adb工具对其进行简单的调试。
adb工具即Android Debug Bridge(安卓调试桥)tools。它就是一个命令行窗口,用于通过电脑端与模拟器或者真实设备交互。
连接至电脑端并输入adb shell即可进入该设备。执行简单的cd和ls命令即可查看里面的文件。
adb工具有2个比较重要的文件传输命令,即adb push sourcefile targetfile和adb pull sourcefile targetfile,一个是将本地文件发送至设备,一个是将设备文件拉取至本地。
例如将设备里面的配置文件信息拉取至本地:1
adb pull iflyos/iFLYOS.json <保存本地路径>
然后打开文件即可。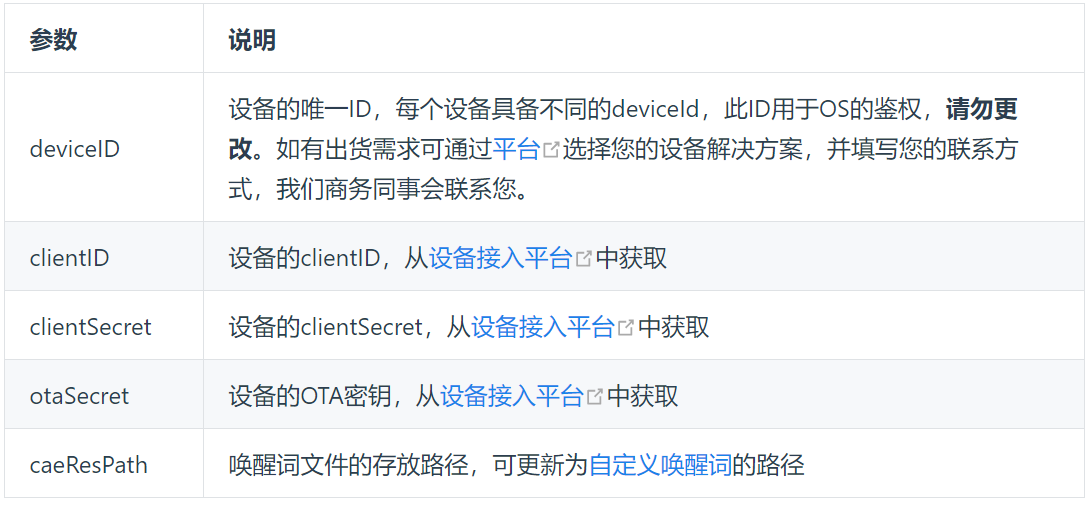
通常,可以先将需要更改的文件先拉取至本地,然后再发送至设备即可。
自定义唤醒词
- 生成唤醒词资源
登录唤醒词平台,输入唤醒词并下载,引擎版本为1566。 - 修改唤醒词资源
将生成好的唤醒词,push到/usr/share/iflyos/ivw/目录下,并在/data/iflyos/iFLYOS.json里修改caeResPath的对应资源路径。
替换完成后,执行adb shell sync生效。
断点重开即可查看效果。
更换提示音
在TTS合成页面选择对应的发音人,生成专属开机欢迎语,推送至设备即可替换。
注:
- 设备的音频文件位置为:
/usr/share/iflyos/ring - 完成替换后需执行
adb shell sync命令生效 - 注意音频文件需转换为
m4a格式 - 替换
ring目录下的音频后,需保持音频文件名前后一致
云端操作系统——iFLYOS
iFLYOS MT8516套件是通过EVS协议与iFLYOS服务端通信实现语音交互和技能调用的。MTK8516套件基于iotjs开发平台实现了与硬件、网络与文件系统等进行交互的能力,并使用JS语言完成了EVS协议逻辑。
iFLYOS是科大讯飞基于人机智能交互技术为广大开发者和第三方厂商开放的全新语音技术服务操作系统。通过先进的人工智能技术让用户的日常生活更方便,获取信息的方式更快捷。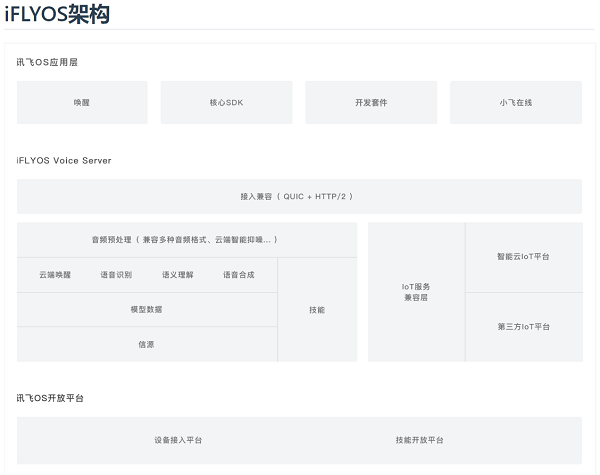
嵌入式协议(Embedded iFLYOS Voice Service, 简称EVS)是一个相对IVS更简单的协议,为厂商接入提供方便,降低设备运行要求,本协议采取websocket进行通讯。
iotjs是三星开源的javascript物联网开发平台。它为javascript应用程序提供了访问硬件、网络、文件系统和异步化的能力,功能类似于nodejs,但无论是代码体积还是内存需求,iotjs都要小很多,是用javascript开发iot(Internet of Things)设备应用程序的首选。
创建设备
打开并登录科大讯飞iFLYOS系统,选择设备接入并添加产品。这里选择linux平台和EVS网络协议。
注:这里的产品信息为自定义名字。
新增技能
选择云端配置->设备能力,找到更多能力,将持续交互能力和儿童模式打开即可。
发布到设备
将MTK8516开发套件的配置文件(/data/iflyos/iFLYOS.json)拉取到本地,将里面的cliend_id和cliend_secret更改为新建设备的信息。并发送至开发套件。
执行adb shell sync并断电重开。
重新进入配网模式,打开手机小飞在线APP,重新配置,并打开里面的持续交互能力和儿童模式功能。
注:第一次发布可能会出现需要授权的问题。选择产品发布->设备ID,找到鉴权失败设备,然后将设备导入授权即可。
自定义问答
选择云端配置->语义理解找到自定义问答,再点击创建自定义问答,然后新建问答库。其模板格式如下: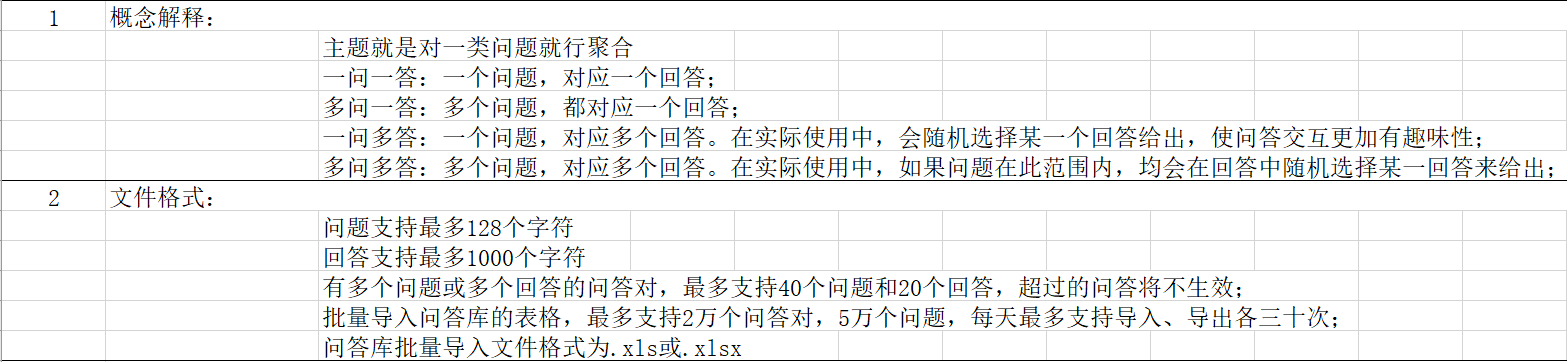
该技能不需要发布到设备,联网即可。
讯飞开发平台
第一部分介绍的是MTK8516开发套件的使用,但其更多的是用于娱乐型的交互,如果需要任务型的交互,还需要使用科大讯飞的开发平台。
打开讯飞开发平台,点击产品服务,可以看到讯飞开发平台提供了很多易操作的服务功能。
创建控制台
点击控制台,创建新应用。
实时语音转写
选择语音识别->实时语音转写,找到实时语音转写API,点击并打开文档。
实时语音转写(Real-time ASR)基于深度全序列卷积神经网络框架,通过WebSocket协议,建立应用与语言转写核心引擎的长连接,开发者可实现将连续的音频流内容,实时识别返回对应的文字流内容。
官方文档已经解释的很清楚了,这里就不多做介绍了。在接口demo里面可以下载官方代码。
AMR小车的语音控制
程序逻辑
整体逻辑比较简单,即语音输入控制指令->小车执行指令->显示任务信息,二者都是基于web实现通讯。
语音代码逻辑
通过阅读官方文档可以看出,实时语音转写主要包含二个阶段:握手阶段和实时通讯阶段。
环境搭建
本博客采用的python语言编写,需要的库为:websocket==0.2.1,websocket-client==0.56.0,requests等。
初始化
1 | # -*- encoding:utf-8 -*- |
创建YunYinModule类,语音实时转写需要的设备参数为base_url,app_id和api_key。result_data存放的是处理的数据。
握手阶段
1 | def createSigna(self): |
所谓握手就是网络通讯连接阶段。主要是生成一个signa。这里官方文档解释的很清楚,可自行学习。
实时通讯阶段
1 | def receiveResult(self): |
实时通讯阶段也就是一个数据处理的阶段,WebSocket协议返回的是一个json格式的数据,也就是代码中的result变量,通过解析该变量得到可处理的result_dict数据。
result_dict字典主要包括action、data等部分,其中当action为started时,表示数据开始接收,当action为result时,表示已经接收到数据,并存放在data中。result_json表示的是实际接收到的语音数据。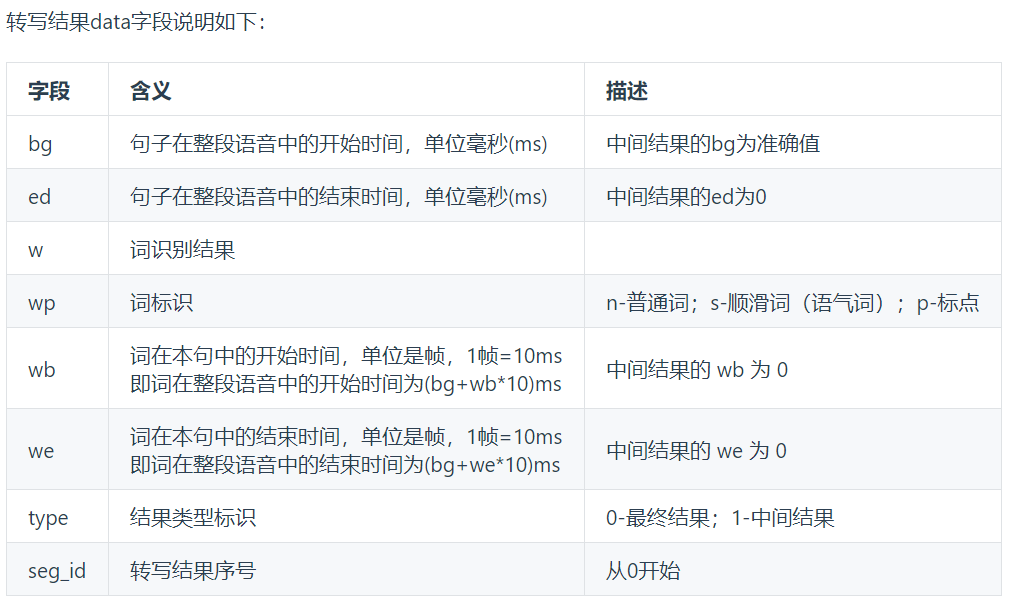
通过分析该表格可知,当we不为0时,表示的是完整的句子(这里完整的意思是,在接收数据时,并不是说完一句完整的话才会显示结果,而是不间断的实时的输出结果,比如你说我要去南京,实际显示的是我,我要去,我要去南京等多个结果,而我们这里只需要最终的结果即可)。
因此在这里添加了一个判断,确保是最后一个完整的句子,然后将原来打散的字符拼接在一起即可。(实际数据输出时,是按单词一个个打散输出的,可print调试观察)
最后加了一个如果输入完毕,则停止交互。
麦克风输入
1 | def sendByMicro(self): |
按照官方文档说明,建议音频流每40ms发送1280字节,采样率为16K。这里需要while循环持续接收语音输入。
AMR小车代码逻辑
初始化
1 | #encoding:utf-8 |
这里主要涉及到swagger-ui的2个接口,即addOrder和onlineAmr,需要的参数为ServerIP和MapID。
addOrder接口
1 | def addOrder(self, amrID="zerg011", targetPoint="P2", times=1): |
该接口是通过web进行通讯,通过requests.pots进行接口调用。这里的heards不需要更改,target参数表示的是地图中的点名称。action表示的是任务类型。其中1指的是休息,2指是充电,4指的是上料,5指的是下料,6指的是拣货。
onlineAmr接口
1 | def checkTaskState(self, amrID): |
该接口查看的是当前调度信息中所有小车的信息。其参数如图所示: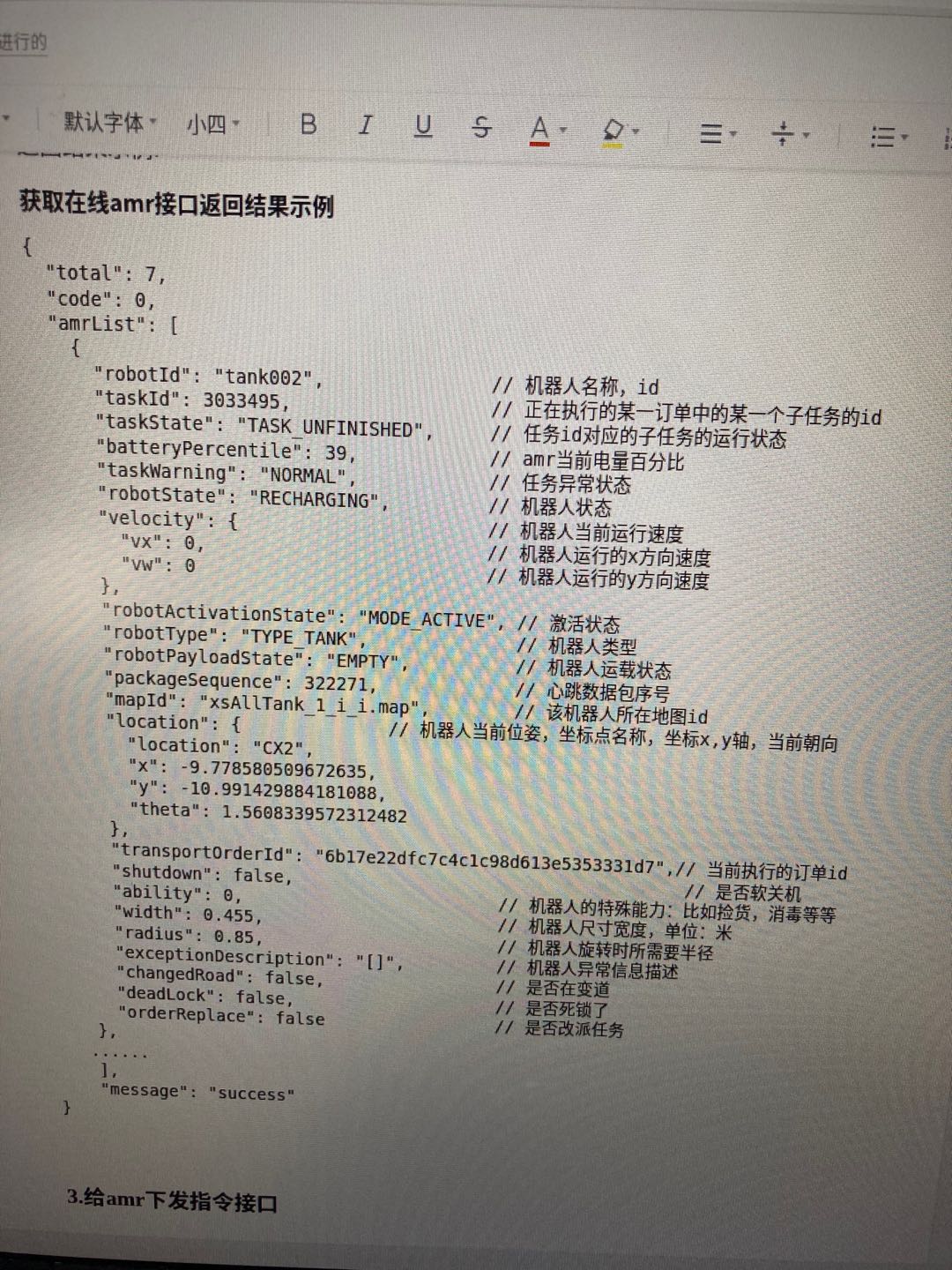
总代码逻辑
1 | from mymoving import MedicalRobotOrder |
这里的参数文件为:1
2
3
4
5
6ServerIP : "192.168.3.18"
MapID : "213xll730"
app_id : "5f1a39b3"
api_key : "d66517a308ba753ebe879506cb95f0c7"
base_url : "wss://rtasr.xfyun.cn/v1/ws"
主函数:1
2
3
4
5
6
7
8
9
10
11
12
13
14if __name__ == "__main__":
with open("param.yml") as stream:
robotParam = yaml.load(stream, Loader=yaml.FullLoader)
# python3.6 可能需要去掉 Loader=yaml.FullLoader
ServerIP = robotParam['ServerIP']
MapID = robotParam['MapID']
app_id = robotParam['app_id']
api_key = robotParam['api_key']
base_url = robotParam['base_url']
myMedicalRobot = MyMedicalRobot(ServerIP, MapID, app_id, api_key, base_url)
myMedicalRobot.test()
首先通过解析参数文件获得参数,然后创建MyMedicalRobot类对象。
由于用户需要不断的输入语音信息,因此需要单独给语音输入开启一个线程,保证能实时获取语音信息。然后通过receiveResult()得到用户输入的语音信息yuYinData,并通过解析语音信息的关键字转换为地图中的信息,最后将该信息发送给小车去执行。