概述
本博客是我的Github上的NAO_GolfVision_ML项目的使用说明。该项目是NAO高尔夫比赛中的视觉系统设计,主要是利用opencv和机器学习算法对视觉系统中的目标进行分类检测。详细的代码解释见另一篇博客:NAO比赛视觉系统设计
平台
Windows 10
python2.7 32(NAO支持的版本)
文件夹结构
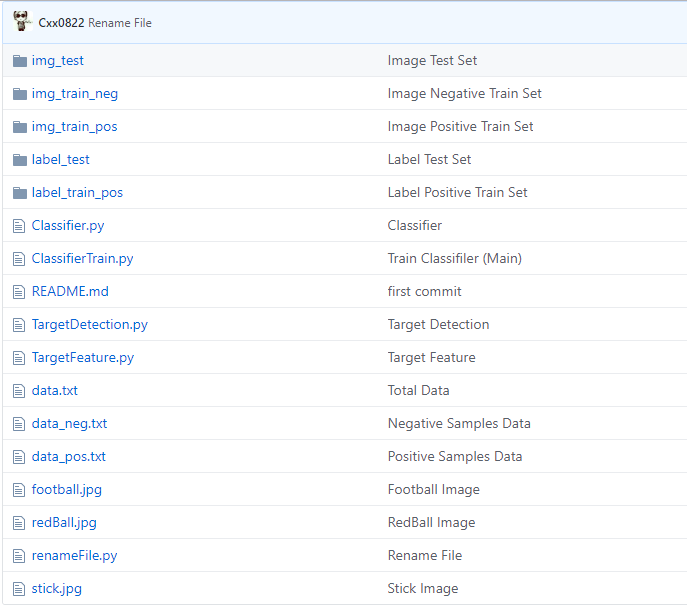
该文件夹主要分为三个部分,第一部分是数据集,包含图片和标签的数据集,其中图片为NAO摄像头实际拍摄的图像,像素大小为640*480,标签为labelImg软件标注生成的xml文件,其中正负样本分开存放。
第二部分是代码,其中TargetDetection.py和TargetFeature.py是opnecv对目标的检测和机器学习对目标的特征提取文件,Classifier,py和ClassifierTrain,py是机器学习的分类器和训练文件。其中ClassifierTrain,py是主函数文件。
第三部分是其他文件,主要包含3张测试图片,即足球、红球和黄杆,3张数据文件,即总数据,正样本数据和负样本数据,另外包含一个renamefile.py,主要是为了统一图片和标签的名字。
TargetDetection.py
该文件包含3个类,其中TargetDetection是基类,HoughDetection是霍夫圆检测类,ContoursDetection是轮廓检测类。读者也可以使用其他检测算法新建自己的检测类。
TargetDetection
该类包含图像预处理函数preProcess(),滤波函数filter()和滑动条函数sliderObjectHSV()。
使用方法
1 | if __name__ == '__main__': |
首先打开一张测试图片,实际比赛中可以将此替换为NAO拍摄的图片,然后实例化类,并调用滑动条函数。注意图片名字和类别名字要一致。 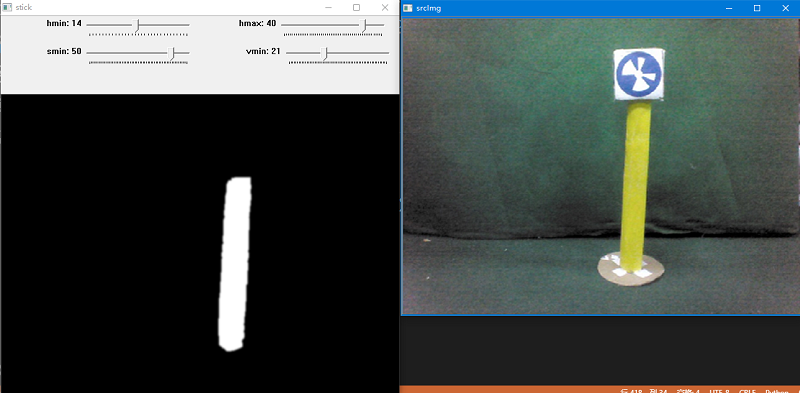
不断调整滑动条的参数,以得到理想效果。
HoughDetection
该类包含霍夫圆检测函数houghDetection(),信息转换函数circle2Rect(),显示结果函数showHoughResult()和霍夫圆检测滑动条函数houghSlider()。
使用方法
1 | if __name__ == '__main__': |
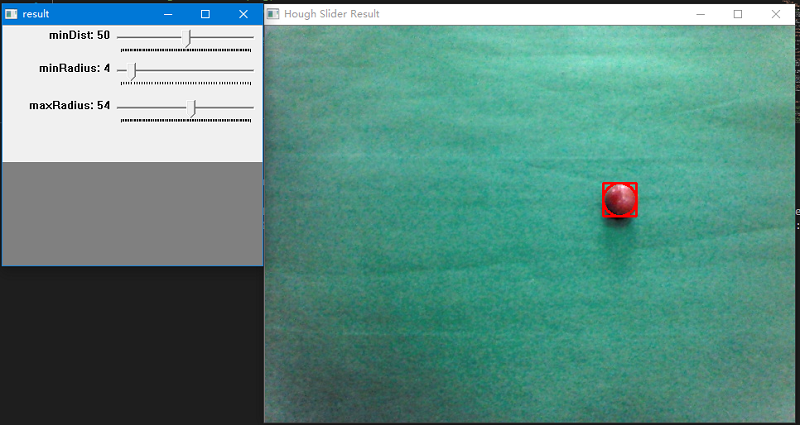
不断调整滑动条的参数,以得到理想效果。
ContoursDetection
该类包含轮廓检测函数contoursDetection(),信息转换函数contour2Rect(),显示结果函数showContourResult()和轮廓检测滑动条函数contoursSlider()。
使用方法
1 | if __name__ == '__main__': |
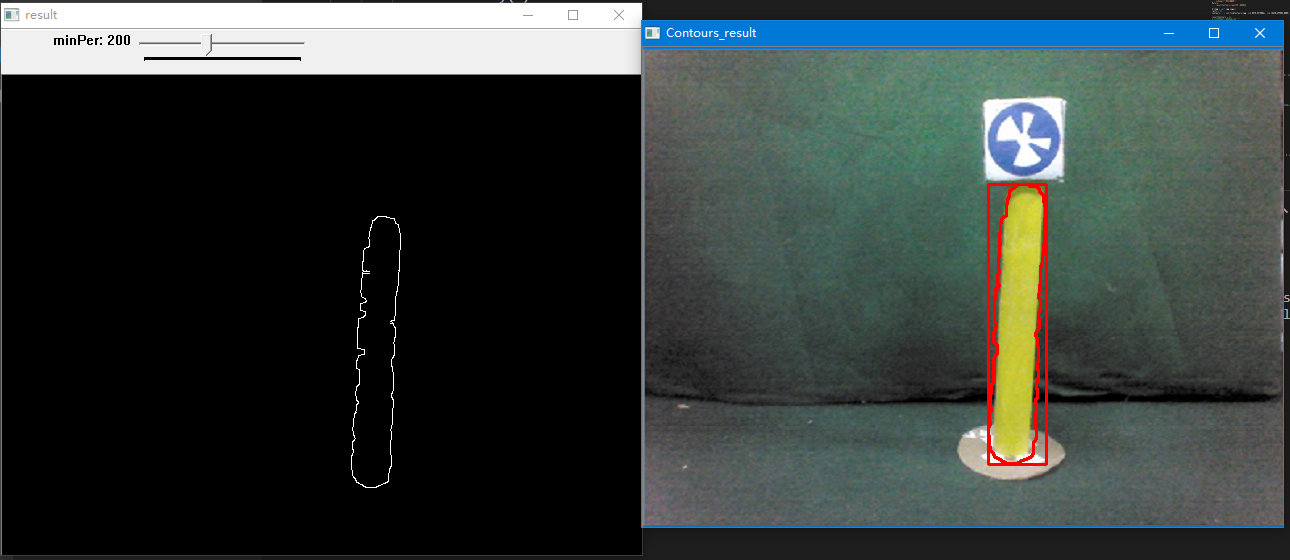
不断调整滑动条的参数,以得到理想效果。
TargetFeature.py
该文件包含2个类,其中HogFeature是提取HOG特征,ColorFeature是提取颜色特征。读者也可以使用其他特征提取算法。最后统一成向量的形式即可。
使用方法
这部分主要是结合之后的分类器训练使用。
Classifier.py
该文件包含2个类,其中Logistic是逻辑回归分类器,KNN是K近邻分类器。读者也可以使用自己的分类器。
使用方法
这部分主要是结合之后的分类器训练使用。
ClassifierTrain.py
该文件包含以下函数:
parseXml():解析标注文件函数,reshapeBallRect():重造球类目标矩形框函数,reshapeStickRect():重造黄杆类目标矩形框函数,circle2Rect():转换信息函数,calColorFeature():计算颜色特征函数,calHOGFeature():计算HOG特征函数,calPosVector():计算正样本向量函数calNegVector():计算负样本向量函数resultTest():分类结果测试函数
使用方法
首先将数据集正确的放入到文件夹中,越多越好,至少上百张,其次更改calPosVector()函数里面的路径位置及信息。
其中画图部分的函数,即:1
2
3
4
5 # cv2.rectangle(srcImg, (newInitX, newInitY), (newEndX, newEndY), (0, 0, 255), 2) # 画矩形
# cv2.imshow("test " + str(i), srcImg)
# cv2.waitKey(300)
# cv2.destroyAllWindows()
在实际训练时需要注释掉,否则会把标注框也认为是正样本。该部分主要是为了测试标注框是否准确,读者可以先保留该部分运行一遍,再注释后运行一遍,实际的特征向量以加了注释后的为准。
1 | if __name__ == '__main__': |
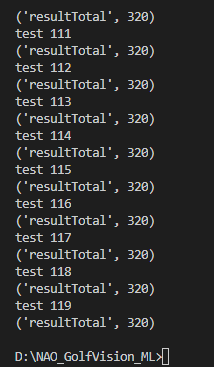
运行过程中,会显示出特征向量的总数,如果是320则是正确的,当然了如果读者自己加入了其他的特征提取,可以自己算一遍。
最后所有的特征向量会存放在data_pos.txt的文件夹下。
负样本的使用方法同上。其最终的特征向量会存放在data_neg.txt文件夹下,最后将这2个txt文件的数据合并到data.txt文件中。
最后再调用测试分类结果函数resultTest()即可,在里面输入相应的分类器,当然也可以是自己的。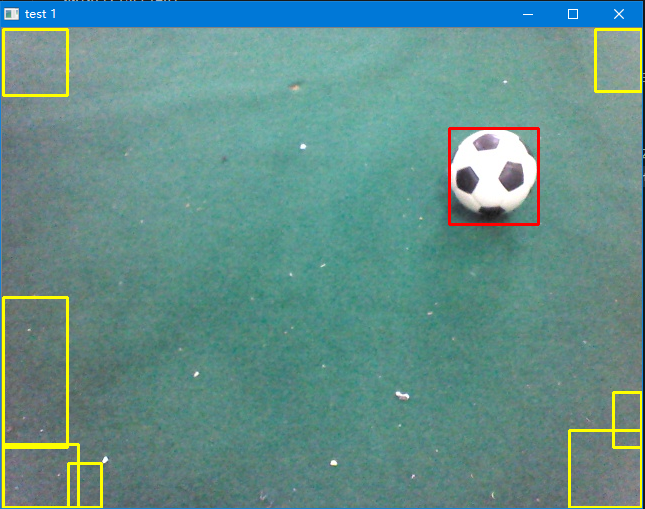
最终结果如图所示,红色为正确的,黄色为错误的。实际测试发现,只要目标不在边界上,其正确率几乎可以达到100%,对于边界上的情况,个别几个情况分类错误,但这对比赛也并没有太大的影响。整体效果还是非常不错的,可以达到比赛的实时检测要求。
注:我这里只对足球类目标进行了检测,没用对红球和黄杆测试,读者有兴趣的话可以自己采集数据并测试一下,欢迎大家留言讨论。
附:sklearn机器学习库实现分类器
这里提供一个强大的机器学习库sklearn来实现之前的分类器,首先需要通过pip安装(pip install -U scikit-learn),由于NAO本身并不支持这个第三方库,所以我们如果要使用的话,需要将下载好的sklearn库上传至NAO中。
和之前一样,还是新建一个py文件,里面可以新建若干各类,每个类实现一个分类器。
实现原理
sklearn实现机器学习算法特别简单,大致可以分为三步,1.读取数据,2.构建分类器并训练参数,3.使用分类器预测。
下面以Logistic回归为例,详细讲解:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52import sklearn
from sklearn.linear_model import LogisticRegressionCV, LinearRegression
from sklearn.model_selection import train_test_split
import numpy as np
from sklearn.externals import joblib
class LogisticSk(object):
def __init__(self, filename):
self.filename = filename
def file2matrix(self):
fr = open(self.filename)
arrayOfLines = fr.readlines()
numberOfLines = len(arrayOfLines)
returnMat = np.zeros((numberOfLines, 320))
classLabelVector = []
index = 0
for line in arrayOfLines:
line = line.strip()
listFromLine = line.split(' ')
returnMat[index, :] = listFromLine[0:320]
if listFromLine[-1] == '0':
classLabelVector.append(0)
elif listFromLine[-1] == '1':
classLabelVector.append(1)
index += 1
return returnMat, classLabelVector
def trainClassify(self):
X, Y = self.file2matrix()
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.1, random_state=0)
lr = LogisticRegressionCV(multi_class="ovr", fit_intercept=True, Cs=np.logspace(-2, 2, 20), cv=2, penalty="l2", solver="lbfgs", tol=0.01)
lr.fit(X_train, Y_train)
return lr
def saveClassify(self, model, path):
joblib.dump(model, path)
def readClassify(self, path):
return joblib.load(path)
def predictClassify(self, lr, X_test):
Y_predict = lr.predict(X_test)
return Y_predict
这里为了和之前的变量名不一样,在分类器后面加了SK,表示是用sklearn库实现的。
读取数据
这部分可以参考之前的file2matrix()函数。
构建分类器并训练
在构建分类器之前,我们可以先用train_test_split()函数将数据集分为训练集和测试集,以便后续的分析(当然也可以直接用原来的数据)。
接下来就是使用sklearn库中自带的分类器训练,这里注意首先要将分类器所在的类导入进来,比如这里是LogisticRegressionCV()分类器函数,它是在sklearn.linear_model类中的。然后可以设置分类器的参数,当然也可以使用默认值。最后使用fit()函数训练以得到相应的参数。
保存和读取模型
训练一次数据集通常需要花费一定的时间,这对实时性的要求显然是不利的,所以通常的做法是先将训练好的模型保存下来,然后再读取。
sklearn中保存和读取的模块是joblib(也有其他的),其dump()和load()函数分别是读取和保存。
注:保存的模型一般后缀名为.m。
使用模型预测
使用predict()函数预测即可,输入参数为待预测的数据。
结果分析
实际测试下来发现,sklearn库的分类器函数和自己写的分类器的效果几乎差不多,总体效果还是比较好的。