概述
只是整理,不展开叙述
平台
Ubuntu / Windows
python3.5 / 3.6
目标分类数据集
目标分类的数据集通常为若干个类别文件夹,然后每个文件夹存放着若干个该类别的图片。数据集通常由图片+类别标签组成的。图片是不需要标注的。
文件夹设置
首先新建一个文件夹dataSet(当然可以取其他名字,下同),然后新建2个文件夹test和val分别存放训练集数据和验证集数据,另外在新建1个文件夹record保存tfrecords数据格式的文件:1
2
3
4dataSet
record
test
val

获取数据集
目标分类的数据集的大小尽可能地小一点,仅包含分类物体即可,如下面的几个图片:

可以从网上获取或自己拍摄采集。
放入数据集
在test和val文件夹下依次新建分类的类别文件夹,并将数据集放入各自的文件夹中。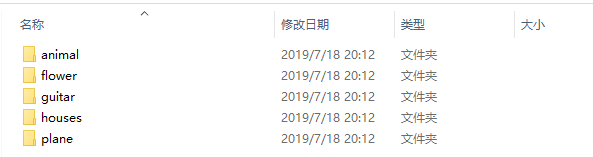
生成数据集文本文件
这一步主要是生成记录数据集路径的txt文件,以便后续读取方便。
create_labels_files.py1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46# -*-coding:utf-8-*-
import os
import os.path
def get_files_list(dir):
files_list = []
for parent, dirnames, filenames in os.walk(dir):
for filename in filenames:
curr_file = parent.split(os.sep)[-1]
if curr_file == 'flower':
labels = 0
elif curr_file == 'guitar':
labels = 1
elif curr_file == 'animal':
labels = 2
elif curr_file == 'houses':
labels = 3
elif curr_file == 'plane':
labels = 4
files_list.append([os.path.join(curr_file, filename), labels])
return files_list
def write_txt(content, filename, mode='w'):
with open(filename, mode) as f:
for line in content:
str_line = ""
for col, data in enumerate(line):
if not col == len(line) - 1:
str_line = str_line + str(data) + " "
else:
str_line = str_line + str(data) + "\n"
f.write(str_line)
if __name__ == '__main__':
train_dir = 'dataSet/train'
train_txt = 'dataSet/train.txt'
train_data = get_files_list(train_dir)
write_txt(train_data, train_txt, mode='w')
val_dir = 'dataSet/val'
val_txt = 'dataSet/val.txt'
val_data = get_files_list(val_dir)
write_txt(val_data, val_txt, mode='w')
生成的train.txt: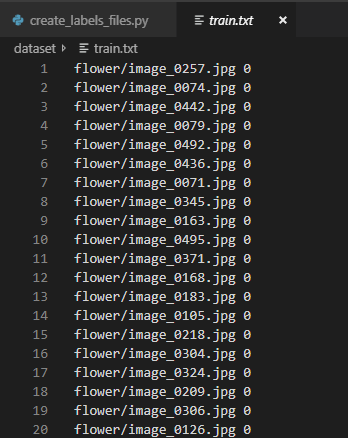
制作tfrecords数据格式
create_tf_record.py,主要的函数为:
- create_records():用于制作records数据的函数;
- read_records():用于读取records数据的函数;
- get_batch_images():用于生成批训练数据的函数;
- get_example_nums:统计tf_records图像的个数(example个数);
- disp_records(): 解析record文件,并显示图片,主要用于验证生成record文件是否成功。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205# -*-coding: utf-8 -*-
import tensorflow as tf
import numpy as np
import os
import cv2
import matplotlib.pyplot as plt
import random
from PIL import Image
def _int64_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
def _bytes_feature(value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
def float_list_feature(value):
return tf.train.Feature(float_list=tf.train.FloatList(value=value))
def get_example_nums(tf_records_filenames):
nums = 0
for record in tf.python_io.tf_record_iterator(tf_records_filenames):
nums += 1
return nums
def show_image(title, image):
plt.imshow(image)
plt.axis('on')
plt.title(title)
plt.show()
def load_labels_file(filename, labels_num=1, shuffle=False):
images = []
labels = []
with open(filename) as f:
lines_list = f.readlines()
if shuffle:
random.shuffle(lines_list)
for lines in lines_list:
line = lines.rstrip().split(' ')
label = []
for i in range(labels_num):
label.append(int(line[i + 1]))
images.append(line[0])
labels.append(label)
return images, labels
def read_image(filename, resize_height, resize_width, normalization=False):
bgr_image = cv2.imread(filename)
if len(bgr_image.shape) == 2:
print("Warning:gray image", filename)
bgr_image = cv2.cvtColor(bgr_image, cv2.COLOR_GRAY2BGR)
rgb_image = cv2.cvtColor(bgr_image, cv2.COLOR_BGR2RGB)
if resize_height > 0 and resize_width > 0:
rgb_image = cv2.resize(rgb_image, (resize_width, resize_height))
rgb_image = np.asanyarray(rgb_image)
if normalization:
rgb_image = rgb_image / 255.0
return rgb_image
def get_batch_images(images, labels, batch_size, labels_nums, one_hot=False, shuffle=False, num_threads=1):
min_after_dequeue = 200
capacity = min_after_dequeue + 3 * batch_size
if shuffle:
images_batch, labels_batch = tf.train.shuffle_batch([images, labels],
batch_size=batch_size,
capacity=capacity,
min_after_dequeue=min_after_dequeue,
num_threads=num_threads)
else:
images_batch, labels_batch = tf.train.batch([images, labels],
batch_size=batch_size,
capacity=capacity,
num_threads=num_threads)
if one_hot:
labels_batch = tf.one_hot(labels_batch, labels_nums, 1, 0)
return images_batch, labels_batch
def read_records(filename, resize_height, resize_width, type=None):
filename_queue = tf.train.string_input_producer([filename])
reader = tf.TFRecordReader()
_, serialized_example = reader.read(filename_queue)
features = tf.parse_single_example(
serialized_example,
features={
'image_raw': tf.FixedLenFeature([], tf.string),
'height': tf.FixedLenFeature([], tf.int64),
'width': tf.FixedLenFeature([], tf.int64),
'depth': tf.FixedLenFeature([], tf.int64),
'label': tf.FixedLenFeature([], tf.int64)
}
)
tf_image = tf.decode_raw(features['image_raw'], tf.uint8)
tf_height = features['height']
tf_width = features['width']
tf_depth = features['depth']
tf_label = tf.cast(features['label'], tf.int32)
tf_image = tf.reshape(tf_image, [resize_height, resize_width, 3])
if type is None:
tf_image = tf.cast(tf_image, tf.float32)
elif type == 'normalization':
tf_image = tf.cast(tf_image, tf.float32) * (1. / 255.0)
elif type == 'centralization':
tf_image = tf.cast(tf_image, tf.float32) * (1. / 255) - 0.5
return tf_image, tf_label
def create_records(image_dir, file, output_record_dir, resize_height, resize_width, shuffle, log=5):
images_list, labels_list = load_labels_file(file, 1, shuffle)
writer = tf.python_io.TFRecordWriter(output_record_dir)
for i, [image_name, labels] in enumerate(zip(images_list, labels_list)):
image_path = os.path.join(image_dir, images_list[i])
if not os.path.exists(image_path):
print('Err:no image', image_path)
continue
image = read_image(image_path, resize_height, resize_width)
image_raw = image.tostring()
if i % log == 0 or i == len(images_list) - 1:
print('------------processing:%d-th------------' % (i))
print('current image_path=%s' % (image_path), 'shape:{}'.format(image.shape), 'labels:{}'.format(labels))
label = labels[0]
example = tf.train.Example(features=tf.train.Features(feature={
'image_raw': _bytes_feature(image_raw),
'height': _int64_feature(image.shape[0]),
'width': _int64_feature(image.shape[1]),
'depth': _int64_feature(image.shape[2]),
'label': _int64_feature(label)
}))
writer.write(example.SerializeToString())
writer.close()
def disp_records(record_file, resize_height, resize_width, show_nums=4):
tf_image, tf_label = read_records(record_file, resize_height, resize_width, type='normalization')
init_op = tf.initialize_all_variables()
with tf.Session() as sess:
sess.run(init_op)
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
for i in range(show_nums):
image, label = sess.run([tf_image, tf_label])
print('shape:{},tpye:{},labels:{}'.format(image.shape, image.dtype, label))
show_image("image:%d" % (label), image)
coord.request_stop()
coord.join(threads)
def batch_test(record_file, resize_height, resize_width):
tf_image, tf_label = read_records(record_file, resize_height, resize_width, type='normalization')
image_batch, label_batch = get_batch_images(tf_image, tf_label, batch_size=4, labels_nums=5, one_hot=False, shuffle=False)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
for i in range(4):
images, labels = sess.run([image_batch, label_batch])
show_image("image", images[0, :, :, :])
print('shape:{},tpye:{},labels:{}'.format(images.shape, images.dtype, labels))
coord.request_stop()
coord.join(threads)
if __name__ == '__main__':
resize_height = 299
resize_width = 299
shuffle = True
log = 5
image_dir = 'dataSet/train'
train_labels = 'dataSet/train.txt'
train_record_output = 'dataSet/record/train{}.tfrecords'.format(resize_height)
create_records(image_dir, train_labels, train_record_output, resize_height, resize_width, shuffle, log)
train_nums = get_example_nums(train_record_output)
print("save train example nums={}".format(train_nums))
image_dir = 'dataSet/val'
val_labels = 'dataSet/val.txt'
val_record_output = 'dataSet/record/val{}.tfrecords'.format(resize_height)
create_records(image_dir, val_labels, val_record_output, resize_height, resize_width, shuffle,log)
val_nums = get_example_nums(val_record_output)
print("save val example nums={}".format(val_nums))
batch_test(train_record_output, resize_height, resize_width)
目标检测数据集
目标检测数据集的格式一般为VOC格式,即由图片文件夹,标注文件夹和txt图片信息文件夹组成。
文件夹设置
首先新建一个文件夹VOCdevkit,然后在里面在新建1个文件夹VOC2019(当然也可以取其他年份),然后新建3个文件夹Annotations,ImageSets和JPEGImages,其中ImageSets文件夹下再新建一个Main文件夹,在里面新建4个txt文件:test.txt,train.txt,trainval.txt,val.txt。1
2
3
4
5
6
7
8
9
10VOCdevkit
VOC2019
Annotations
ImageSets
Main
test.txt
train.txt
trainval.txt
val.txt
JPEGImages
获取数据集
目标检测的数据集的大小一般要比目标分类的大一些,可以包含多个检测目标,最后还需要对每个数据集利用标注软件进行标注。
标注数据集
软件:labelImg
放入数据集
将数据集图片放入到JPEGImages文件夹中,其对应的标注文件放入到Annotations中,然后在VOC2019下新建一个可以产生txt文件的py文件:create_label.py: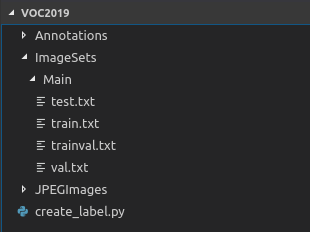
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36import os
import random
trainval_percent = 0.2
train_percent = 0.8
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
首先将数据集8:2分成train.txt和trainval.txt,然后再将trainval.txt再8:2分成test.txt和val.txt。
生成数据集文本文件
对于目标检测来说,还需要生成一个包含数据集路径、标注框信息和类别信息的txt文件。在最外面的文件夹在新建一个转换文件:voc_annotation.py:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33import xml.etree.ElementTree as ET
from os import getcwd
sets=[('2019', 'train'), ('2019', 'val'), ('2019', 'test')]
classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
def convert_annotation(year, image_id, list_file):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
tree=ET.parse(in_file)
root = tree.getroot()
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (int(xmlbox.find('xmin').text), int(xmlbox.find('ymin').text), int(xmlbox.find('xmax').text), int(xmlbox.find('ymax').text))
list_file.write(" " + ",".join([str(a) for a in b]) + ',' + str(cls_id))
wd = getcwd()
for year, image_set in sets:
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg'%(wd, year, image_id))
convert_annotation(year, image_id, list_file)
list_file.write('\n')
list_file.close()
更改相应的信息,最后运行会生成3个txt文件,即2019_train.txt,2019_test.txt和2019_val.txt。