摘要
平台
系统:Ubuntu
框架:Darknet
配置环境
opencv配置
下载opencv3.4.0
从官网下载即可,网址,选择Sources源代码,尽量选择3.4.0及以下的版本,高版本的不一定能配置成功。
安装依赖
依次执行下面4条命令即可。
sudo apt-get install gcc g++ cmake pkg-config build-essentialsudo apt-get install build-essential cmake git libgtk2.0-dev pkg-config libavcodec-dev libavformat-dev libswscale-devsudo apt-get install python-dev python-numpy libavcodec-dev libavformat-dev libswscale-devsudo apt-get install libgtk2.0-dev libavcodec-dev libavformat-dev libtiff4-dev libswscale-dev libjasper-dev
注:安装过程中,有yes/no选项时,选择yes即可。
编译
刚才从官网下载的只是opencv的源码,我们还要对其编译后才能正常使用。
cd进入到opencv文件夹,比如我的opencv位置是在home目录下:cd opencv-3.4.0- 新建一个文件夹
build:mkdir build cd进入到build文件夹:cd buildcmake编译:cmake -D CMAKE_BUILD_TYPE=RELEASE -D CMAKE_INSTALL_PREFIX=/usr/local ..
这里需要下载一个压缩包,如果网络环境不好的话,可能会卡很长时间,这里我们可以先离线下载好压缩包。
首先在github网站上找到压缩包并下载,网址,然后再打开opencv文件夹内的3rdparty/ippicv里面的ippicv.cmake文件,并将里面的压缩包下载网址改为本地的文件路径,如file://Downloads。最后再重新执行上面命名即可。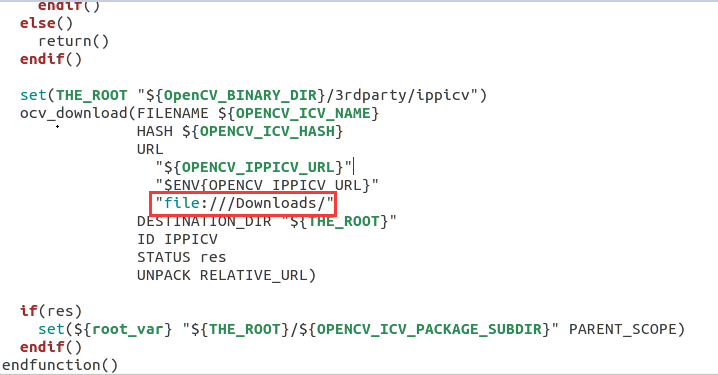
make -j8sudo make install
环境配置
最后添加Ubuntu的环境变量就全部完成了。
- 首先将
OpenCV的库添加到路径:sudo gedit /etc/ld.so.conf.d/opencv.conf
执行此命令后打开的可能是一个空白的文件,在文件末尾添加:/usr/local/lib
注:这里很多博客都这么写,我当时也这么做的,但实际运行时,仍然报错,说找不到libopencv_highgui.so.3.4文件,后来才发现我的这个文件并不在该路径下,而是在该路径下的x86_64-linux-gnu文件夹内,所以正确的应该是/usr/local/lib/x86_64-linux-gnu。所以读者在实际配置时,这里填的应该是libopencv_highgui.so.3.4文件的上一级文件夹路径。 - 生效配置文件:
sudo ldconfig - 配置bash:
sudo gedit /etc/bash.bashrc
在末尾添加:PKG_CONFIG_PATH=$PKG_CONFIG_PATH:/usr/local/lib/pkgconfig export PKG_CONFIG_PATH
保存,执行如下命令使得配置生效:source /etc/bash.bashrc
更新:sudo updatedb
至此,所有opencv的配置都已经完成。
darknet配置
下载源代码
登陆darknet官网,在里面找到其GitHub地址,然后下载即可。
注:如果读者想在Windows上使用YOLO,可以自己新建build文件夹编译,也可以使用别人的:网址。
然后解压缩,并cd进入该文件夹下,输入make指令编译:1
2cd darknet-master
make
在继续输入./darknet,如果没有报错,则配置成功。
更改配置文件
打开里面的Makefile文件,修改里面的配置信息,如果装了GPU,将GPU和CUDNN设置为1,如果装了opnecv,将OPENCV设置为1。(我这里只装了opencv)
下载权重
进入darknet官网中,选择里面的YOLO选项,进入YOLO主页,在里面找到权重的下载地址,点击下载即可。
注:可能会很慢,可以找别人下好的百度云下载。
测试
输入下面指令:1
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
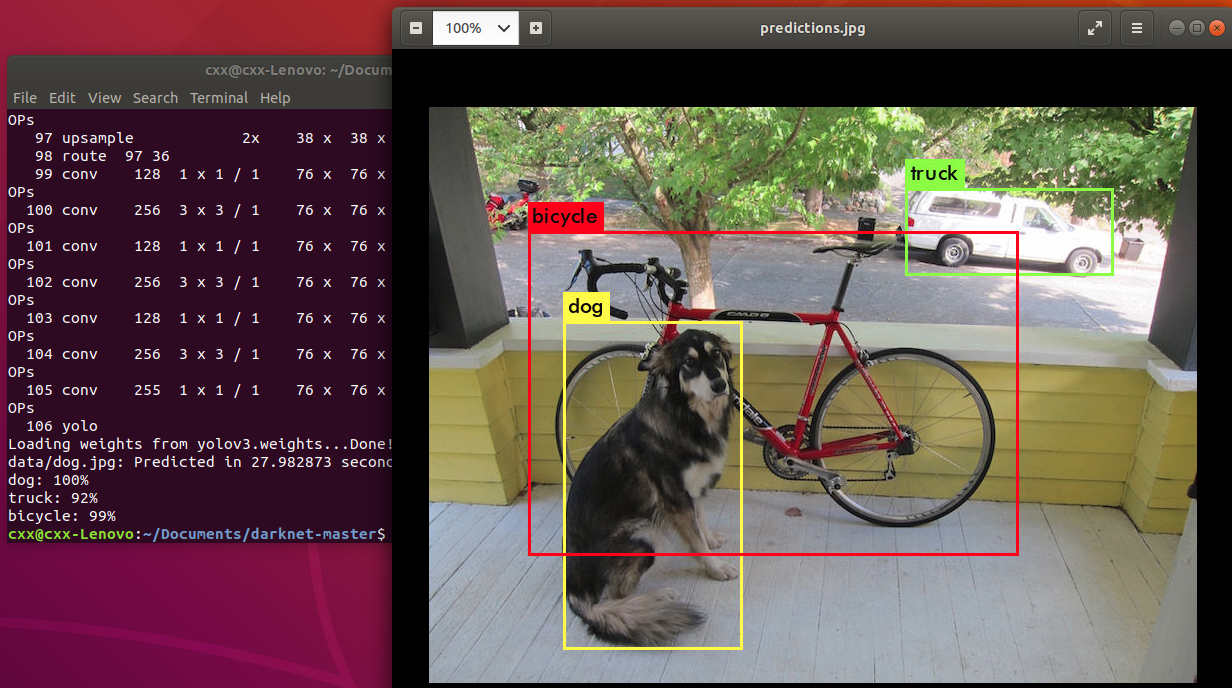
最终的结果如图所示,生成每个类别的概率信息和标注框信息。
初识darknet
源代码框架
cfg:存放的是各种常见网络结构的配置文件,如yolo、rcnn等,如果想要定义自己的网络结构需要编写自己的cfg文件;
data:各种数据集;
examples:存放的各种检测算法的例子,如detector.c就是检测的代码,根据你输入run_detector函数的参数是train还是test转到其内部的train_detector或者test_detector,此文件夹中最重要的文件是darknet.c;
include:只有一个文件darknet.h是darknet的头文件,主要是一些定义和函数声明;
scripts:几个shell脚本,用来获取数据集的;
src:绝大部分的源码,里面有BN层的实现、卷积层的实现、正则化等等。
编译
编译好了,这时我们会发现文件夹里多出了obj、backup、results三个文件夹和libdarknet.a静态库、libdarknet.so动态库。动态链接的基本思想简单来说,就是不对那些组成程序的目标文件进行链接,而是当程序运行时才进行链接,从而解决了静态链接空间浪费的问题。obj文件夹下就是所有目标文件,backup文件夹主要存放训练的模型,result文件夹主要存放训练的结果。
简单使用
darknet的使用也是很简单,我们先在darknet官网上下载好已经训练出的yolov3的权重,之后在终端运行:1
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
这个命令结合代码非常好理解,我们首先在examples文件夹下的darknet.c文件里面找到darknet的主函数: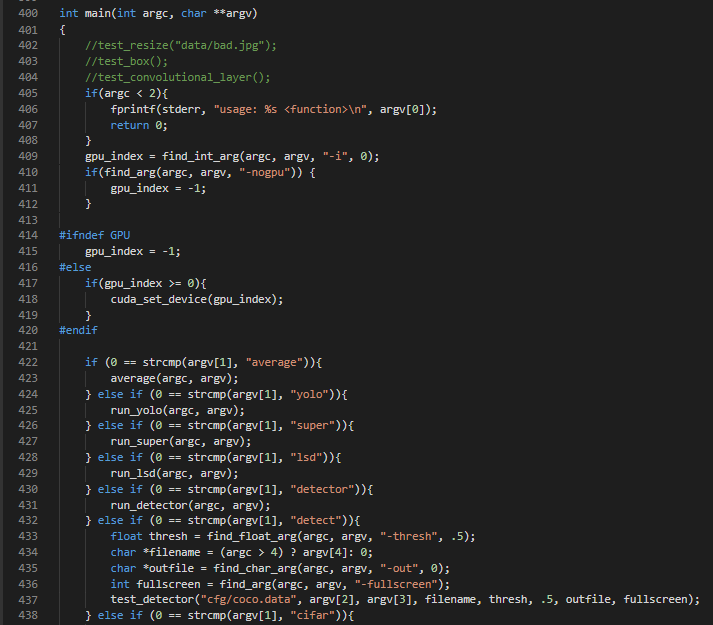
这是主函数的部分截图,可以看出该程序是根据给定的argv(命令行参数)来决定程序的走向,如本例argv[1](命令行的第一个参数,下同)为detect,根据主函数中的第6个if判断语句可以看出,该程序会转到test_dector函数中,也就是测试检测,后面的args[2]、args[3]、args[4]都是该函数的形参。那test_dector()函数又是什么意思呢?
这个函数的定义并不在当前的darknet.c文件中,在第8行可以看到其使用了extern来声明这是一个外部函数,该函数是在examples文件夹下的detector.c文件里面,其函数头为:1
void test_detector(char *datacfg, char *cfgfile, char *weightfile, char *filename, float thresh, float hier_thresh, char *outfile, int fullscreen)
该函数由darknet.c中的主函数调用,该函数为一个前向推理测试函数,不包括训练过程,因此如果要使用该函数,必须提前训练好网络,并加载训练好的网络参数文件。
其主要参数含义为:
datacfg:数据集信息文件路径(也即cfg/*.data文件),文件中包含有关数据集的信息,比如cfg/coco.data;
cfgfile:网络配置文件路径(也即cfg/*.cfg文件),包含一个网络所有的结构参数,比如cfg/yolo.cfg;
weightfile:已经训练好的网络权重文件路径,比如darknet网站上下载的yolo.weights文件;
filename:待进行检测的图片路径(单张图片)。
综上所述,这个命令代码的含义就是:运用yolov3.cfg的网络框架和yolov3.weights权重去测试dog.jpg这张图片并显示结果。其中数据集为默认的coco.data。当然了,我们也可以使用其他的网络结构去测试其他图片。
初识Yolo
目标检测
在正式讲解yolo之前,我们先简单了解一下计算机视觉中的目标检测。
图像分类是计算机视觉最基本的任务之一,在图像分类的基础上,还有更复杂和有意思的任务,如目标检测,物体定位,图像分割等。其中目标检测是一件比较实际的且具有挑战性的计算机视觉任务,其可以看成图像分类与定位的结合,给定一张图片,目标检测系统要能够识别出图片的目标并给出其位置。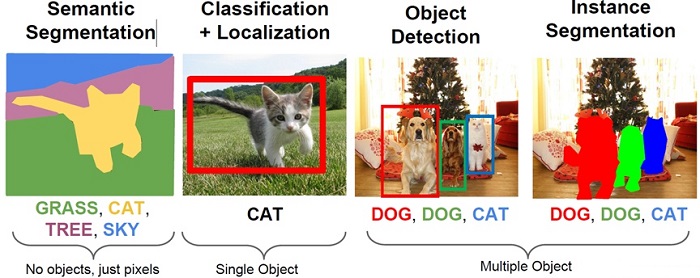
最近几年比较流行的目标检测算法可以分为两类,一类是基于Region Proposal(候选区域)的R-CNN系算法(R-CNN,Fast R-CNN, Faster R-CNN),它们是two-stage(两步走)的,需要先使用启发式方法(selective search)或者CNN网络(RPN)产生Region Proposal,然后再在Region Proposal上做分类与回归。而另一类是Yolo,SSD这类one-stage(一步走)算法,其仅仅使用一个CNN网络直接预测不同目标的类别与位置。
第一类方法是准确度高一些,但是速度慢,但是第二类算法是速度快,但是准确性要低一些。这可以在下图中看到。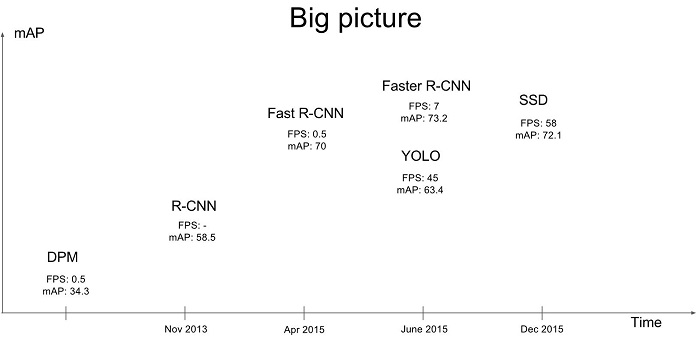
其中FPS表示每秒帧率,用来评估速度,mAP表示多类别的平均精度,用来评估准确率。
Yolo名称含义
Yolo其全称是You Only Look Once: Unified, Real-Time Object Detection,这个题目取得非常好,基本上把Yolo算法的特点概括全了:You Only Look Once说的是只需要一次CNN运算,Unified指的是这是一个统一的框架,提供end-to-end的预测,而Real-Time体现是Yolo算法速度快。
Yolo之前的目标检测思想
在Yolo出现之前,目标检测中比较常用的思想是滑动窗口技术。其基本原理就是采用不同大小和比例(宽高比)的窗口在整张图片上以一定的步长进行滑动,然后对这些窗口对应的区域做图像分类,这样就可以实现对整张图片的检测了,如下图所示,如DPM就是采用这种思路。
但是这个方法有致命的缺点,就是你并不知道要检测的目标大小是什么规模,所以你要设置不同大小和比例的窗口去滑动,而且还要选取合适的步长。但是这样会产生很多的子区域,并且都要经过分类器去做预测,这需要很大的计算量,所以你的分类器不能太复杂,因为要保证速度。解决思路之一就是减少要分类的子区域,这就是R-CNN的一个改进策略,其采用了selective search(选择性搜索)方法来找到最有可能包含目标的子区域(Region Proposal),其实可以看成采用启发式方法过滤掉很多子区域,这会提升效率。
Yolo的检测思想
Yolo算法不再是窗口滑动了,而是直接将原始图片分割成互不重合的小方块,然后通过卷积直接生成特征图,我们可以认为特征图的每个元素也是对应原始图片的一个小方块,然后用每个元素来可以预测那些中心点在该小方格内的目标,这就是Yolo算法的朴素思想。
整体来看,Yolo算法采用一个单独的CNN模型实现end-to-end的目标检测,整个系统如下图所示:首先将输入图片resize到448x448,然后送入CNN网络,最后处理网络预测结果得到检测的目标。相比R-CNN算法,其是一个统一的框架,其速度更快,而且Yolo的训练过程也是end-to-end的。也就是这里的窗口就是整幅图片。
再看Darknet——测试自己的数据集
之前我们使用了Yolo作者提供的数据集和权重系数来预测图片,那我们该如何建立自己的数据集和权重系数呢?
数据集配置
Yolo属于有监督学习,即事先知道分类的标签值,所以我们需要采集大量的数据集供Yolo学习。下面以检测黄杆为例,讲解如何配置数据集。
重命名数据集
我们采集到的数据集可以是从网上找的,也可以是手机拍摄的,也可以是从视频里面截取的等等,但往往其命名格式都是互不相同,如果没有一个统一的命名规则,直接训练的话,显然不是太好,所以我们首先要将采集到的数据集统一命名:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18import os
def rename_files(dir_path):
"""
批量重命名文件
参数:
dirPath:文件路径
"""
file_list = os.listdir(dir_path)
index = 0
for item in file_list:
oldname = dir_path + r"\\" + file_list[index]
newname = dir_path + r"\\" + ".jpg"
os.rename(oldname, newname)
index += 1
这段代码的作用就是把文件夹下的图片依次命名为:0.jpg,1.jpg…,当然你也可以自己设置命名规则。代码比较简单,就不多做讲解了。
标注数据集
有了数据集,接下来就是对数据集的每张照片进行人工标注了。这里推荐使用标注软件labelImg(自行百度下载即可),其使用方法也十分简单。
首先打开data中的predefined_classes.txt,将其信息修改为要标注的类别,比如stick,有几类就写多少。然后打开软件,首先选择Open Dir打开图像文件夹,然后选择Change Save Dir选择要保存的xml文件的文件路径(标注完成后会生成一个xml文件存放标注信息),然后点击Create RectBox创建矩形。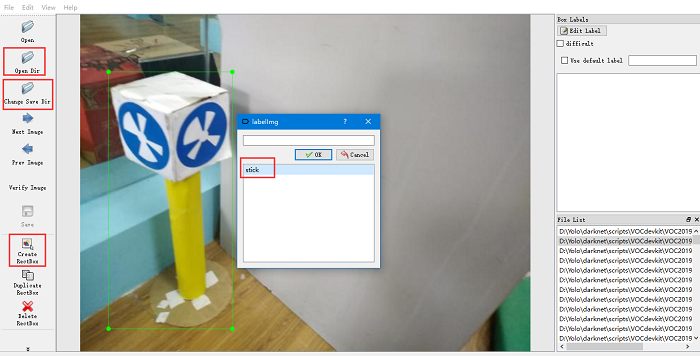
在需要的区域拖拽鼠标即可,然后在弹出的对话框中选择类别的名称,最后点击save保存,并选择Next Image切换到下一张。这时就可以看到保存xml文件夹中会出现对应照片的xml文件了。
准备数据集
有了原始数据集和标注文件后,我们就可以配置属于Yolo的数据集了。
首先创建一个文件夹VOCdevkit,当然你也可以起个其他的名字,只不过Yolo作者是这么做的,其源代码也是照着这个来的,所以一般就起这个就可以了。然后将其放入到scripts文件夹下,因为后续要使用的vov_label.py在该文件夹下,所以会比较方便。然后再依次新建下列文件夹,最终的文件目录如下:1
2
3
4
5
6VOCdevkit
——VOC2019 #文件夹的年份可以自己取
————Annotations #放入所有的xml文件
————ImageSets
——————Main
————JPEGImages #放入所有的图片文件
然后我们把图片放入JPEGImages文件夹中,把标注文件放入Annotations文件夹中。其中Main文件夹下需要再新建4个txt文件,分别为:test.txt(测试集),train.txt(训练集),val.txt(验证集),trainval.txt(训练和验证集),其中训练集和验证集是必须的,所以这里我只新建了2个txt文件。
生成train.txt和val.txt
这两个文本文件存放的就是训练集和验证集中图片的文件名,注意这里只是文件名,不包含后缀。我们可以使用下面的voc_train.py(自己新建,放在scripts文件夹下)生成:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24import os
from os import listdir, getcwd
from os.path import join
if __name__ == '__main__':
source_folder='/home/cxx/Desktop/darknet/scripts/VOCdevkit/VOC2019/JPEGImages/'
dest='/home/cxx/Desktop/darknet/scripts/VOCdevkit/VOC2019/ImageSets/Main/train.txt'
dest2='/home/cxx/Desktop/darknet/scripts/VOCdevkit/VOC2019/ImageSets/Main/val.txt'
file_list=os.listdir(source_folder)
train_file=open(dest,'a')
val_file=open(dest2,'a')
for file_obj in file_list:
file_path=os.path.join(source_folder,file_obj)
file_name,file_extend=os.path.splitext(file_obj)
file_num=int(file_name)
if(file_num<150):
train_file.write(file_name+'\n')
else :
val_file.write(file_name+'\n')
train_file.close()
val_file.close()
这里的源文件夹就是刚才放图片的文件夹JPEGImages(路径根据情况自行修改),目标文件就是我们新建的train.txt和val.txt,然后利用splitext()分离文件名和后缀名。这里面的判断条件file_num<150,可以根据需求自行修改,因为我这里只有300张数据集,所以将前150张作为训练集,后150张作为验证集。
然后运行指令:python voc_train.py即可。打开Main文件夹中的train.txt和val.txt可以看出里面存放着图片的文件名了。(这里奇怪的是,代码中并没有乱序的函数,为啥生成的文件名是乱序的。)
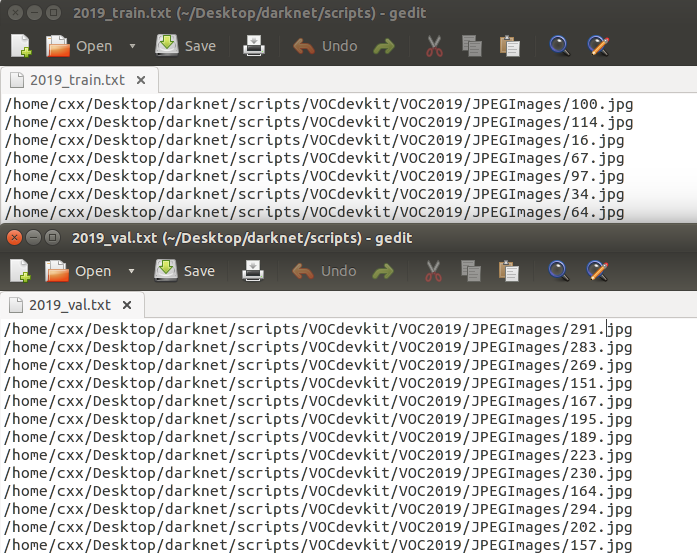
生成2019_train.txt、2019_val.txt、train.txt
有了刚才图片的文件名信息,我们就可以生成Yolo需要的图片路径信息和标注框信息了。这里Yolo的作者提供了相应的python转换代码voc_train.py(在scripts文件夹下),修改相应信息直接运行即可:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('2019', 'train'), ('2019', 'val')]
classes = ["stick"]
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
os.system("cat 2019_train.txt 2019_val.txt > train.txt")
最后一行的意思是将2个文件合并到一个文件里面。
首先将sets和classes列表中的内容更改为自己的,其中set里面的2019就是刚才新建文件夹的年份,后面的train和val就是Main文件夹中的2个txt文件。classes就是分类的类别,我这里只有1类,就是stick。最后将最后一行的文件夹名字更改一下即可。
然后运行指令:python voc_label.py即可。打开VOC2019文件夹,可以看到里面有1个新的文件夹labels,打开可以发现就是刚才的标注框的信息,即[类别,x,y,w,h]。在scipts文件夹下,可以看到新建了3个txt文件,里面存放的是数据集的绝对路径,待会修改配置文件的时候需要用到。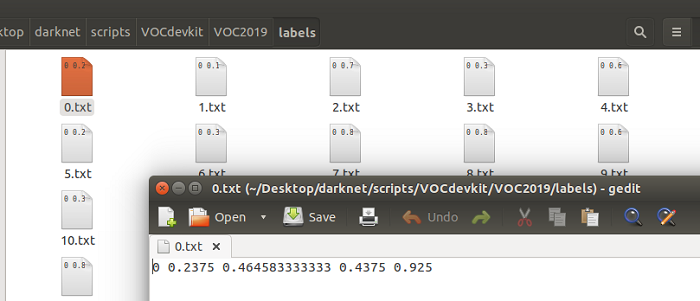
至此数据集的配置工作终于弄完了,下面就是修改一些配置文件了,相对来说比较轻松。
下载预先权重
在修改配置文件之前,我们先下载一个权重系数文件。这里我们为什么要下载别人的权重系数,不直接自己训练出来呢?因为如果我们不使用别人的,通常的做法是随机生成一个,但我们的网络结构很大,一旦随机的不好,刚开始的时候其效果将会非常不好,导致训练的次数和时间上升,而如果用别人训练好的,虽然检测的目标不一样,但至少比随机产生的要好很多,收敛也会加快。其实这也就是迁移学习的思想。
运行指令wget https://pjreddie.com/media/files/darknet53.conv.74下载即可,如果下载较慢,可以将网址复制到浏览器中下载。下载完放在scripts文件夹中。
修改配置文件
我们一共要修改3个配置文件。
cfg/voc.data
根据目录找到该文件,并打开:1
2
3
4
5classes= 1 #classes为训练样本集的类别总数
train = /home/cxx/Desktop/darknet/scripts/2019_train.txt #train的路径为训练样本集所在的路径
valid = /home/cxx/Desktop/darknet/scripts/2019_train.txt #valid的路径为验证样本集所在的路径
names = data/voc.names #names的路径为data/voc.names文件所在的路径
backup = backup
比较简单,修改即可。最好是完整的路径。
data/voc.name
根据目录找到该文件,并打开:1
stick #修改为自己样本集的标签名
比较简单,修改即可。
cfg/yolov3-voc.cfg
根据目录找到该文件,并打开。这里比较复杂,一共需要更改2个部分,共四处地方。
第一部分是[net]部分,就是网络结构的参数。原始文件中batch = 64,subdivision = 16,其含义为每轮迭代会从所有训练集里随机抽取batch = 64个样本参与训练,所有这些 batch个样本又被均分为subdivision = 16次送入网络参与训练,以减轻内存占用的压力。
这看起来很好,但如果显卡不行或者显存不够大的话,训练会很慢甚至崩溃掉,所以电脑不好的可以将这2个值改小一点,注意值最好是2的幂次。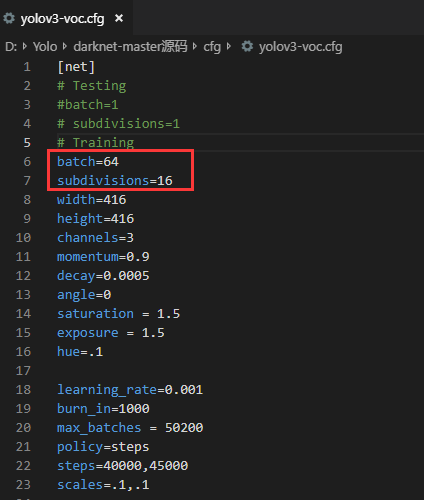
第二部分是softmax层的修改,也就是[yolo]和上一个[convolutional],一共有3处yolo,每处都同样的改法。
首先是[convolutional]中的filters大小,其计算公式为:3*(classes+5),这里我的classes为1,所以更改为:3*(1+5)=18,其次是[yolo]中的classes,更改为1。最后的random,如果显存不好,将其设置为0。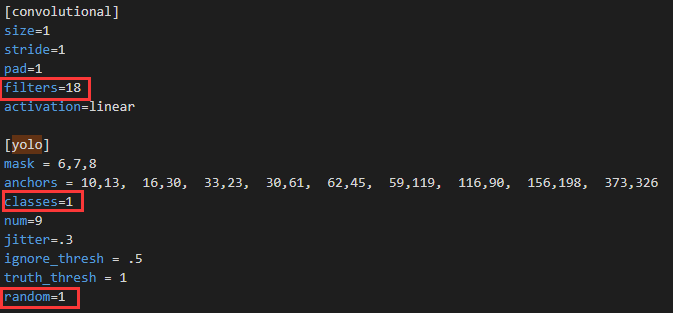
至此,所有的配置都弄好了,下面我们就可以正式训练了。
开始训练
训练指令十分简单,一行命令即可:1
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg scripts/darknet53.conv.74 -gpus 0,1
注意相应的文件路径,如果是cpu训练的话,就把后面的gpu删掉即可。
配置文件详解及问题
再看Yolo——内部原理
Unified Detection(统一检测)
首先将输入的图片分割成S*S的网格,然后每个单元格负责去检测那些中心点落在该格子内的目标。这句话比较绕口,可以反过来理解,即如果一个目标的中心点在某个单元格内,那么这个单元格就要负责预测这个目标(数据集都是提前标注好的,事先是知道每个目标的中心点的。)。例如在下图中,狗这个目标的中心落在左下角一个单元格内(第5行第2列),那么该单元格负责预测这个狗。(对于单元格内没有目标的,当然就不用检测了,这里可以通过后面的公式看出,直接把没目标的单元格过滤掉了。)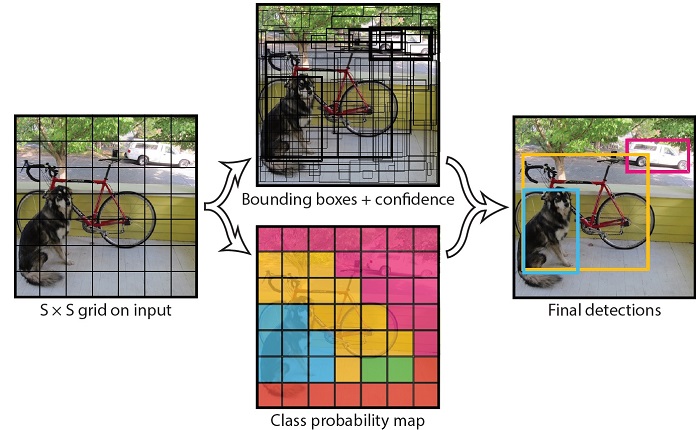
bounding box
每个单元格一共会预测B个边界框bounding box(下图中间上面的黑色小框),其中每个bounding box都包含5个confidence score(置信度得分):[x,y,w,h,confidence]。其中x,y指的是bounding box的中心点坐标,w,h指的是bounding box的宽和高,confidence是置信度,具体由后面的公式计算得出。
例如在YOLOv1中,S和B的取值为7和2,也就是一共有7*7*2=98个bounding box。
其实这个和之前的two-stage目标检测算法,如CNN类似,这里的边界框相当于之前的候选区域,只不过之前是用滑动窗口来选择,这里采用的是1个单元格2个框的思想。因为如果是滑动窗口的话,遍历一张图,需要的窗口太多了,计算量很大,而且窗口都是固定大小,不能随意放缩,而且很多窗口都是冗余的。而yolo的思想就是利用置信度里的x,y,w,h来调节窗口的大小。而且每个单元格都会有相应的边界框,也不至于漏掉某个目标的检测。
在YOLOv1中,采取的做法是1个grid cell(单元格)2个bounding box,然后利用后面的损失函数和网络结构不断地修正bounding box里面的参数,直到和真实框相接近。这样做会带来2个不好的结果:1、位置精确性差,对于小目标物体以及物体比较密集的也检测不好,比如一群小鸟。2、虽然可以降低将背景检测为物体的概率,但同时导致召回率较低。所以在YOLOv2中,针对bounding box做了点改进。
anchor box
YOLOv1是利用全连接层直接预测bounding box的坐标,而YOLOv2借鉴了Faster R-CNN的思想,引入了anchor box(锚点框)。所谓锚点框就是提前设定好几个预测框的大小。
在YOLOv2和YOLOv3中,为了得到更加精细的anchor box,其个数和大小都是由K-means聚类算法计算出来的(具体细节可百度其他博客),在YOLOv2中k=5,而YOLOv3中k=9,也就是说,在YOLOv3中,会提前设定好9个anchor box的尺寸大小,这个可以在其源代码中看到:1
10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
每个anchor prior由两个数字组成,一个代表高度另一个代表宽度(当然最后要归一化处理)。这里之所以取9个,是因为v3输出了3个不同尺度的feature map。采用多尺度来对不同尺寸的目标进行检测,越精细的grid cell就可以检测出越精细的物体,每个尺寸3个anchor box,所以一共是9个。如下图左边的框图所示,每个grid cell有9个anchor box(其边框可以超出图像边缘)。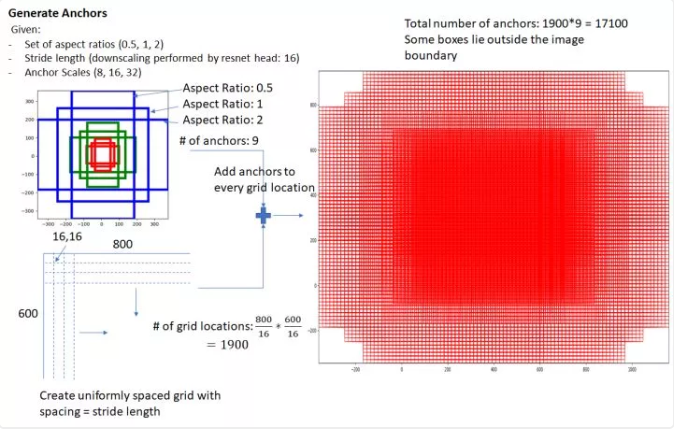
在之前的YOLOv1中,我们一共只有98个预测框,而在YOLOv3中,我们一共有13*13*9=1521(YOLOv3中将网格划分为13*13)。显然,预测框的个数越多,其准确率也就越高。
在YOLOv3中,对anchor box还做了以下的改进:
9个anchor box会被三个输出张量平分的。根据大中小三种size各自取自己的anchor box。- 每个输出y在每个自己的网格都会输出3个预测框,这
3个框是9除以3得到的,这是作者设置的,我们可以从输出张量的维度来看,13x13x255。255是怎么来的呢,3*(5+80)。80表示80个种类,5表示位置信息和置信度,3表示要输出3个prediction。在代码上来看,3*(5+80)中的3是直接由num_anchors//3得到的。 - 作者使用了
logistic回归来对每个anchor box包围的内容进行了一个目标性评分(objectness score)。根据目标性评分来选择anchor prior进行predict,而不是所有anchor prior都会有输出。
虽然现在我们已经有了这么多的预测框,但真正需要的并不多,接下来做的就是,从这么多预测框中筛选出我们需要的,然后在不断调整其参数,直至和真实框相接近。
IOU和NMS
在理解这两个概念之前,我们先看一下bounding box里面的第5个参数confidence的计算公式: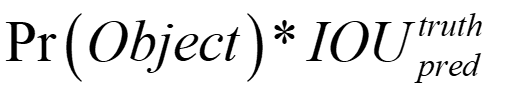
第一项的含义就是,如果grid cell里面没有object,则该项为0,那么confidence就是0,如果有,则为1,那么confidence就等于第二项的值。所以如何判断一个grid cell中是否包含object呢?答案是:如果一个object的ground truth(真实框)的中心点坐标在一个grid cell中,那么这个grid cell就是包含这个object,也就是说这个object的预测就由该grid cell负责。(这一步就过滤掉很多bounding box了。)
第二项是IOU,即交并比,如下图所示:
红色框表示真实框,紫色框表示预测框,交并比的含义就是2个框的交集除以2个框的并集,也就是图中黄色部分除以绿色部分。其值为0时,表示没有重叠,为1时表示完全重叠,我们可以设定一个阈值来判断其预测框是否有目标存在(一般设定为0.5,即IOU的值为0.5时,则认为检测到目标了)。
最后每个grid cell还要预测C个类别概率(YOLO是一个多目标检测),表示一个grid cell在包含object的条件下属于某个类别的概率,所以其最终的计算公式为: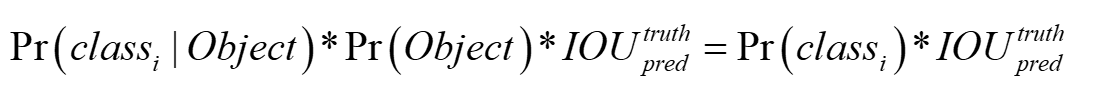
也就是每个bounding box的confidence和每个类别的score相乘,最终得到每个bounding box属于哪一类的confidence score。
但是经过上面几步之后,仍然会存在一些一个目标下很多宽高接近的冗余框,所以最后我们还需要利用NMS(非极大值抑制)去掉重复率较大的bounding box。其原理也十分简单,就是选择IOU最大的那个框。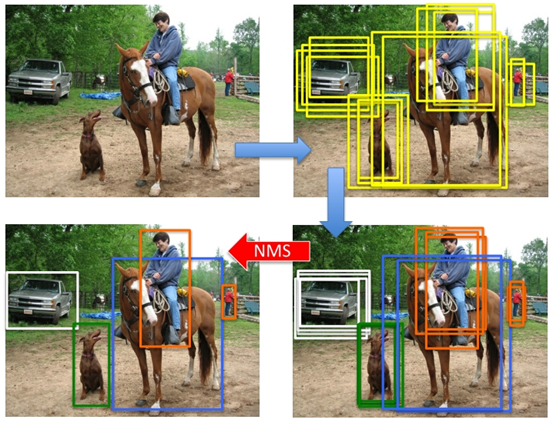
x,y,w,h
对于YOLO中的bounding box部分,还有最后一部分,就是x,y,w,h的理解。在YOLOv1中,对x,y采取的直接预测,其值并没有加过多的限制,也就是说很可能出现anchor box预测的目标离该单元格很远,这样会导致模型不稳定,特别在早期迭代的时候,需要很长时间才能收敛,所以在YOLOv2中对此做了改进:采用相对预测的方法,即每一个anchor box只负责检测周围正负一个单位以内的目标bounding box。其计算公式如下: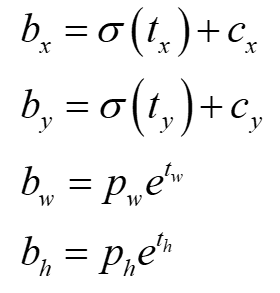
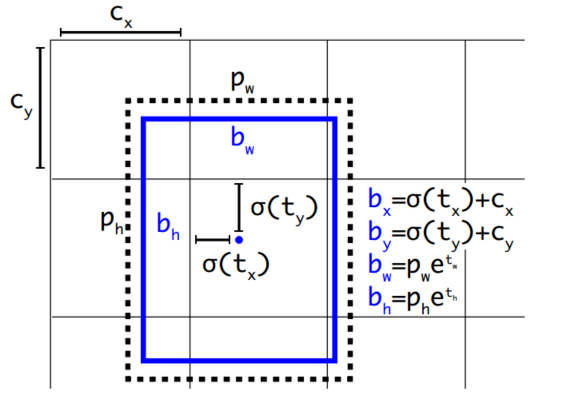
其实就是把预测框的值转换为预测框的实际位置。
黑色虚线框是bounding box,蓝色矩形框就是预测的结果。首先将图像划分成13*13大小的网格,然后每个网格预测5个bounding box,然后每个bounding box预测5个值:tx,ty,tw,th,to(to就是confidence)。cx和cy表示cell和图像左上角的横纵距离,为了保证之前说的每一个anchor box只能预测该单元格内的目标,tx和ty都经过了sigmoid函数处理,这样其值的范围就在0到1之间,这样的归一化处理也使得模型训练更加稳定,当然最后的实际位置要加上之前的横纵距离;pw和ph表示bounding box的宽高,为了保证预测的和实际的之间是一种放缩关系,这里加入了e的指数次方,以保证后面的系数是大于0的。
注:这里采用的思想就是通过平移和放缩来实现预测框和实际框的不断逼近。
总结
总结一下,我对YOLO边界框的理解就是:先用Kmeans人为的设定9个anchor box,然后将输入图片分为S*S个网格,每个网络都将这9个anchor box遍历一遍,然后通过置信度计算公式筛选出最好的边界框,最后通过卷积网络和损失函数不断地训练学习,校正置信度里面(x,y,w,h)四个参数,以得到最好地边框效果。
网络结构
YOLO从v1到v3,其网络结构也经历了较大的变化,从最开始的GoogLeNet到Darknet 53,模型变得越来越复杂,但其运行时间和精度确越来越好。
YOLOv1
v1的网络结构主要是采用GoogLeNet模型,卷积层提取特征,全连接层预测类别概率和坐标。最后输出的结果是7*7*30。但v1稍微对里面的一些细节做了改进:
- 将
Inception Module替换成1*1和3*3的卷积 v1一共有24层卷积,2个全连接层。- 使用
Leaky Relu作为激活函数。 - 在第一个全连接层后面加上一个
ratio=0.5的Dropout层。
训练时,首先利用ImageNet 1000-class的数据集预先训练v1网络中的前20个卷积层和一个平均池化层,最后再加一个全连接层。输入图像的大小为224*224。正是训练时,再采用v1网络,同时输入改为448*448。
YOLOv2
YOLOv2的全名为YOLO9000:Better,Faster,Stronger,无论是精度还是速度上都得到了很大的提升。
这是论文原文里面列出来的YOLOv2针对v1的改进,其中大部分都是针对网络结构的改进。
Batch Normalization
在每一个卷积层后添加batch normalization。
High Resolution Classifier
之前的预训练的输入图像大小是先224*224,然后再448*448,现在的做法是,将输入大小改成448*448,先在ImageNet数据集上训练10轮,这样训练后的网络就可以适应高分辨率的输入了。
New Network
YOLOv2使用了一个新的分类网络作为特征提取部分,作者使用了较多的3*3卷积核,在每一次池化操作后把通道数翻倍。借鉴了network in network的思想,网络使用了全局平均池化,把1*1的卷积核置于3*3的卷积核之间,用来压缩特征。也用了batch normalization稳定模型训练。
最终得出的基础模型就是Darknet-19,如下图,其包含19个卷积层、5个最大值池化层。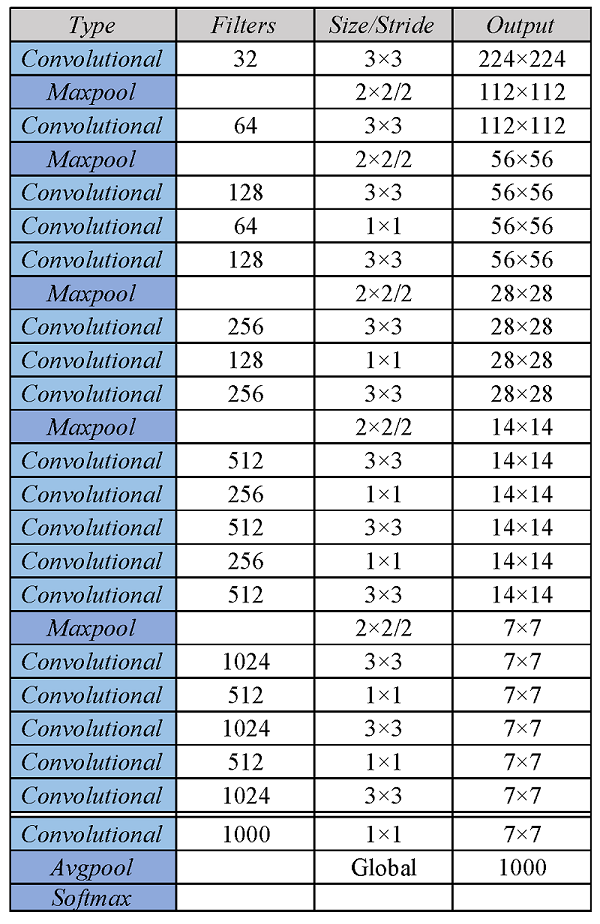
Loss Function
从YOLOv1到YOLOv3中,损失函数几乎没有怎么改变,最多就是把其中几个的均方误差改成了交叉熵形式。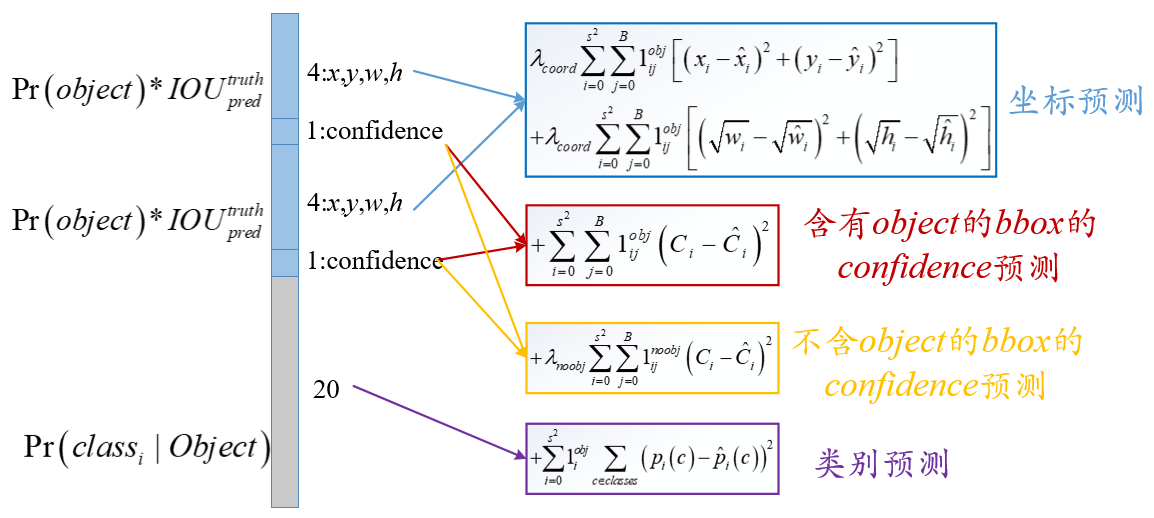
损失函数如上图所示,里面包含3个部分,即坐标预测、bbox预测和类别预测。
坐标预测(坐标损失)
坐标预测为公式中的前两行,第一行是box中心坐标(x,y)的预测,第二行为宽和高的预测。这里是用宽和高的平方根来代替原来的宽和高,这样做主要是因为,相同的宽和高误差,对于小的目标精度影响比大的目标要大。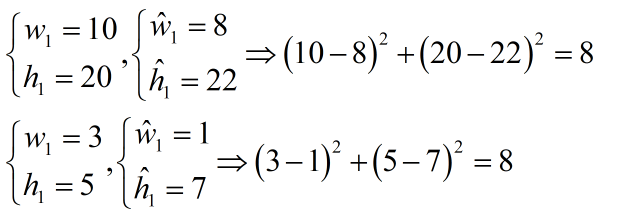
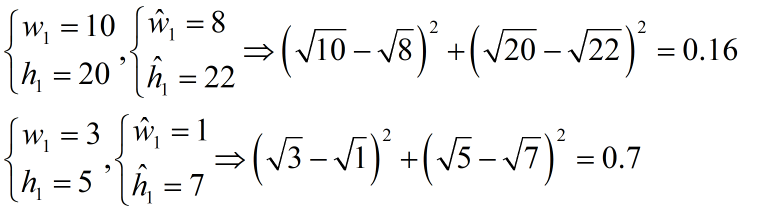
如上图所示,有2组坐标。第一个是不加平方根的,其误差值都一样,但对于加了平方根的,明显小目标的误差更大一点。
这里前面的λ和1系数见下文分析。
bbox预测(confidencd损失)
bbox预测为公式中的第三、四行。第三行为含有object时的置信度(confidence)预测,第四行为不含有时的预测。这里的bbox预测和之前的坐标预测,两者的λ系数是不一样的。
因为很多grid cell是不包含物体的,这样的话很多grid cell的confidence score为0,如果权值一致,容易导致模型不稳定,训练发散。所以可以采用设置不同权重方式来解决,一方面提高坐标预测的权重,另一方面降低没有object的box的confidence loss权值,论文中将这2个权重系数分别设为5和0.5。而对于包含object的box权重系数还是原来的1。
类别预测(分类损失)
第五行表示预测类别的误差,注意前面的系数只有在grid cell包含object的时候才为1。
实现过程
以YOLOv1为例,输入N个图像,每个图像包含M个object,每个object包含4个坐标(x,y,w,h)和1个label。
然后通过网络得到7*7*30大小的三维矩阵。每个1*30的向量前5个元素表示第一个bounding box的4个坐标和1个confidence,后5个元素表示第二个bounding box的4个坐标和1个confidence。最后20个表示这个grid cell所属类别。这30个都是预测的结果,也就是都是网络生成的值。
然后就可以计算损失函数的第一、二 、五行,这一部分比较好理解,x,y,w,h都是输入值,是已知的,前面的1_ij^obj指的是判断第i个网格中第j个bbox是否负责这个object,那怎么判断呢?与object的ground truth box的IOU最大的bbox负责该object,也就是说IOU最大时,此系数为1,否则为0。第五行指的是类别概率,也是输入值,是已知的。其前面的系数1_i^obj表示判断是否有object的中心落在网格i中,也就是说有object时,此系数为1,否则为0 。
比较难理解的是confident的损失。预测的confidence可以根据ground truth和预测的bounding box计算出的IOU,和是否有object的0,1值相乘得到(见上文分析)。而真实的confidence是0或1值,即有object则为1,没有object则为0。(1表示此时IOU最大,也就是真实框)
总结
综上所述,并不是网络的所有输出都要计算loss的,具体地说:
- 有物体中心落入的
grid cell,需要计算分类损失,两个预测框bounding box都要计算置信度损失,预测的bounding box与groud truth中IOU较大的那个预测框bounding box需要计算xywh损失。 - 最关键的部分,没有物体中心落入的
grid cell,只需要计算置信度(confidence)损失。
另一种实现YOLO的框架——Keras
安装环境
首先我们需要安装Tensor Flow框架(直接pip安装即可),如果显卡较好,可以安装GPU版本,具体安装过程这里就不叙述了。其次需要安装Keras框架(直接pip安装即可)。Keras是一个由Python编写的开源人工神经网络库,可以作为Tensorflow、Microsoft-CNTK和Theano的高阶应用程序接口,进行深度学习模型的设计、调试、评估、应用和可视化。最后再下载Keras-YOLO的源代码即可,GitHub网站。
文件结构
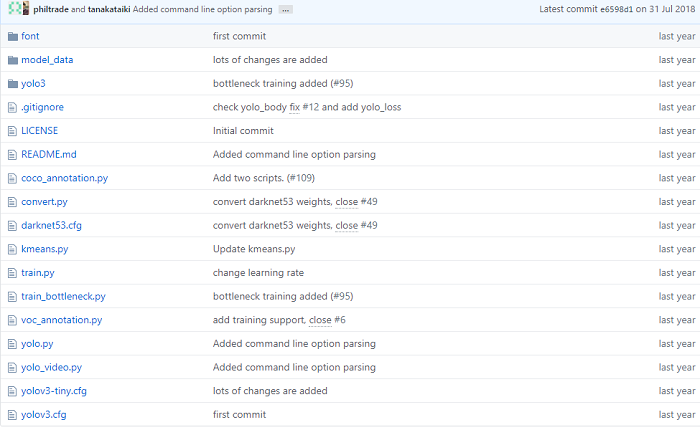
font:字体目录(不知道干啥用的)。model_data:模型数据,主要存放数据集类别信息和anchor的大小。可以更改成自己的数据集信息。yolo3:里面有2个py文件,一个是model.py,就是构建yolo3的主要模块文件,包含网络结构,损失函数等,另一个是utils.py,主要是一些model.py用到的辅助性的工具函数。coco_annoatation.py:将.json文件转换为txt文件,voc_annoatation.py:将.xml文件转换为txt文件。最后生成的txt文件包括训练的图片的路径信息、标注框信息和类别信息。convert.py:把darknet的.weights权重转换为keras的.h5权重文件。kmeans.py:通过聚类得到数据最佳的anchors。train.py:训练yolov3的文件。yolo.py:构建以yolov3为底层构件的yolo检测模型,因为上面的yolov3还是分开的单个函数,功能并没有融合在一起,即使在训练的时候所有的yolov3组件还是分开的功能,并没有统一接口,供在模型训练完成之后,直接使用。通过yolo.py融合所有的组件。yolo_video.py:使用yolo.py文件中的yolo检测模型,并且对视频或图像中的物体进行检测。yolov3.cfg,yolov3-tiny.cfg构建yolov3或yolov3-tiny检测模型的整个超参文件。
快速使用
首先需要下载一个权重文件:网址,然后将权重放在主文件夹下。
执行如下命令将
darknet下的yolov3配置文件转换成keras适用的h5文件:1
python convert.py yolov3.cfg yolov3.weights model_data/yolo.h5
注:可能需要输入python3
运行完会在model_data文件夹下生成yolo.h5文件。
- 运行预测图像程序
1
python yolo_video.py --image
然后根据提示输入图片位置: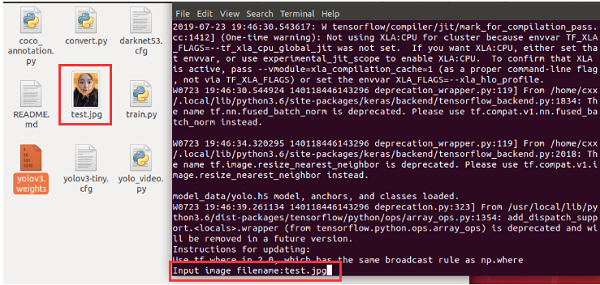
其结果如下所示: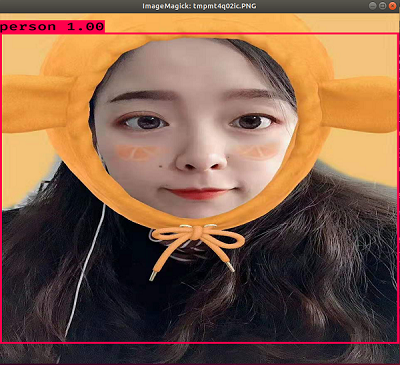
训练自己的数据集
创建数据集文件夹VOCdevkit
在最外面的文件夹下新建一个VOCdevkit文件夹,这里的VOCdevkit文件夹和darknet框架下的是一样的,这里就不再叙述了。
这里提供另一个生成随机数据集的py文件:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36import os
import random
trainval_percent = 0.2
train_percent = 0.8
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
将其放在JPEGImages文件夹的同级目录下,运行后,会在Main文件夹下生成4个txt文件,里面存放着随机的图片名字。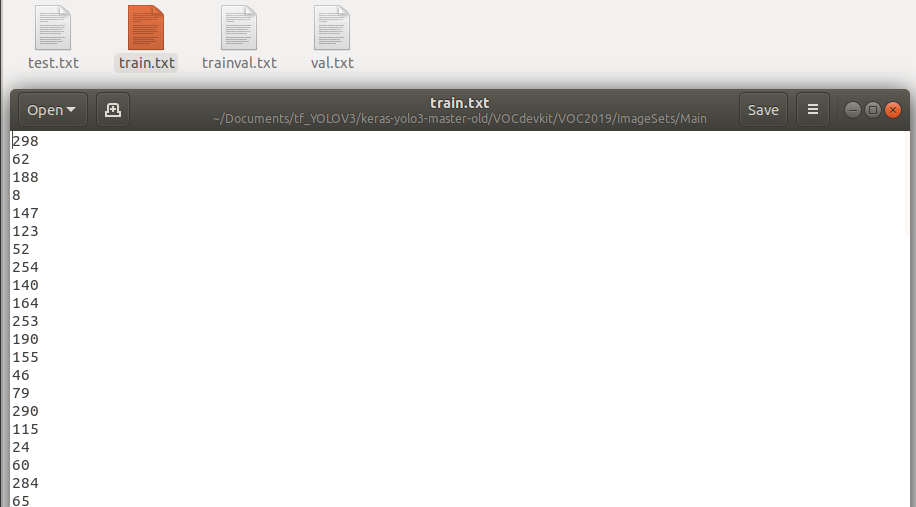
这样我们的VOC数据集就制作完成了。
生成train.txt,val.txt和test.txt
和Darknet一样,这些文件主要包含每张图片的位置信息、标记框的信息和类别信息。打开voc_annotation.py文件,修改sets和classes列表里面的信息,运行即可。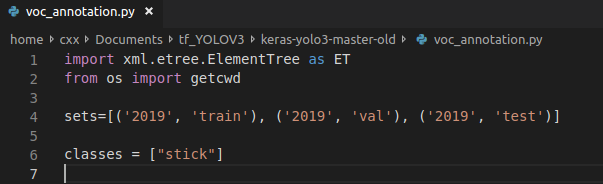
运行结束后会在YOLO的源代码文件夹下产生这些文件。
修改配置文件
这里一共需要修改2个配置文件信息,第一个是model_data文件夹里面的voc_class.txt文件,修改为自己的类别即可。第二个是最外面的文件夹中的训练文件train.py,将_main()函数里面的文件路径更改为自己的即可,注意这里的log日志文件夹需要自己新建。在训练前可以先运行kmeans.py生成最好的anchor box(注意修改里面的文件路径),然后将其放入到model_data文件夹中。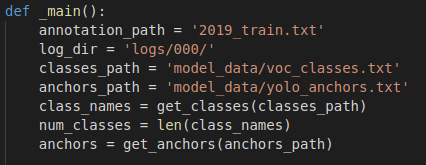
然后直接运行train.py即可训练。
训练
整个训练过程分两次,每次50次迭代。第二次迭代时,如果Loss几乎没有变化会提前终止。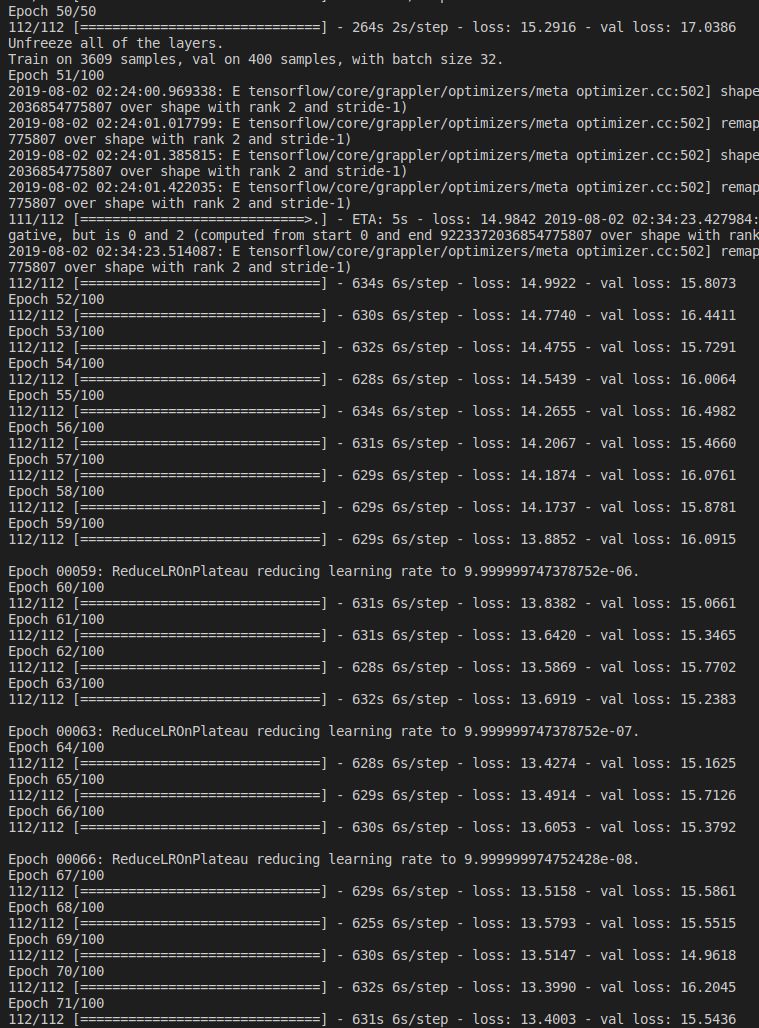
结果分析
训练完之后,我们还可以计算每个类别的平均精度等信息,即AP和mAP等。
下载源代码
首先需要下载2个源代码,网址1,网址2。下载完成后,将里面的内容全部放到YOLO的源代码文件夹中:
生成groundtruths
首先生成真实框的信息,即:<class_name> <left> <top> <right> <bottom> [<difficult>]。
先将class_list.txt里面的内容换成自己的类别信息(我这里用的是VOC2007数据集):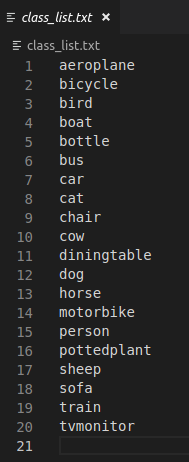
然后运行下面的命令即可:1
python convert_keras-yolo3.py --gt test.txt
convert_keras-yolo3.py就是刚才下载的转换文件,test.txt为测试集的txt文件,(我这里是2019_test.txt),运行结束后,会在from_kerasyolo3文件夹中看到每张图片的真实框信息。(注,可能需要换成python3)。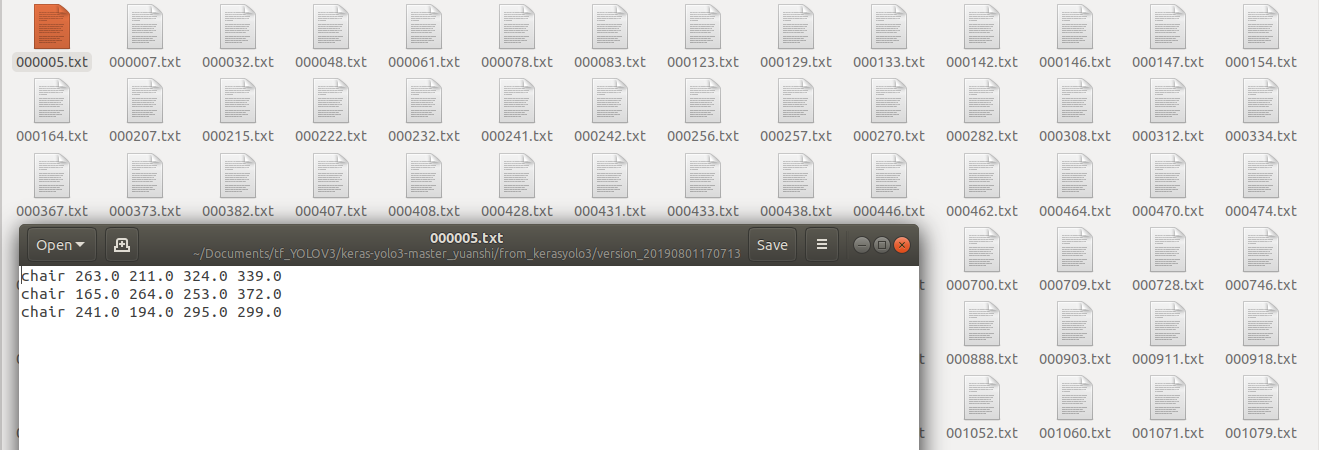
然后将里面所有的txt文件都复制到input->ground-truth文件夹里面。
生成detections
其次生成预测框的信息,即:<class_name> <confidence> <left> <top> <right> <bottom>。
首先更改config.yml里面的信息: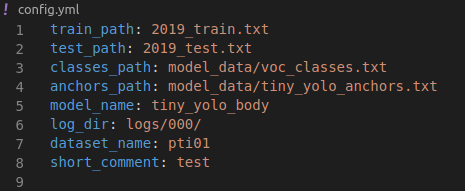
前面4个信息就是一些文件的路径,model_name指的是用的是哪个模型训练的(yolo3文件夹里面的model.py里面的模型),我这里是tiny_yolo_body,当然也可以是自己的模型(此处的模型需要和训练时候的模型一致)。log_dir指的是权重文件的路径,后面2个可以不用改。
然后将刚才下载的文件夹里面的model.py文件替换掉YOLO原始源代码里面的yolo3文件夹里面的model.py。
然后再运行下面的命令:1
python yolo_new.py -g config.yml --weights logs/000/xx.h5
yolo_new.py就是刚才下载的转换文件,xx.h5就是权重文件。(可能要装一个第三方库)
程序会显示一共用了多少时间和每个图片预测的时间。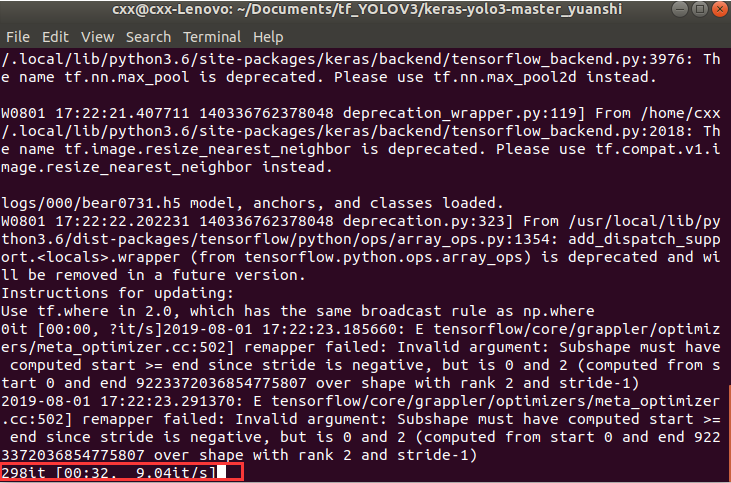
程序运行结束后,会在源代码文件夹中生成一个名字很长的txt文件,将其重命名为pred.txt。
最后运行下面的命令即可:1
python convert_keras-yolo3.py --pred pred.txt
运行结束后,会在from_kerasyolo3文件夹中看到每张图片的预测框信息: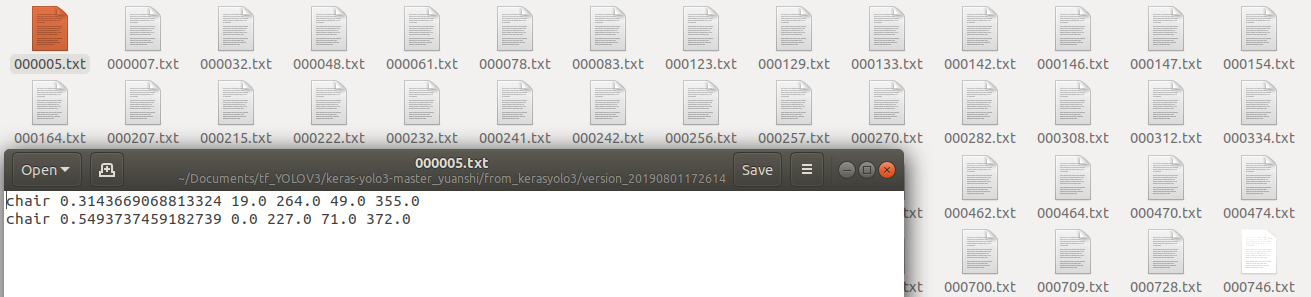
然后将里面所有的txt文件都复制到input->detection_results文件夹里面。
运行main.py
在运行main.py之前,还需要将测试集的图片放到input->images-optional里面,虽然这一步原作者写的是可选,但如果不做的话程序会报错。(为了方便,可以把所有数据集都拷过来)
最后就是运行main.py了,如果装了Opencv的话,会看到很酷的动画。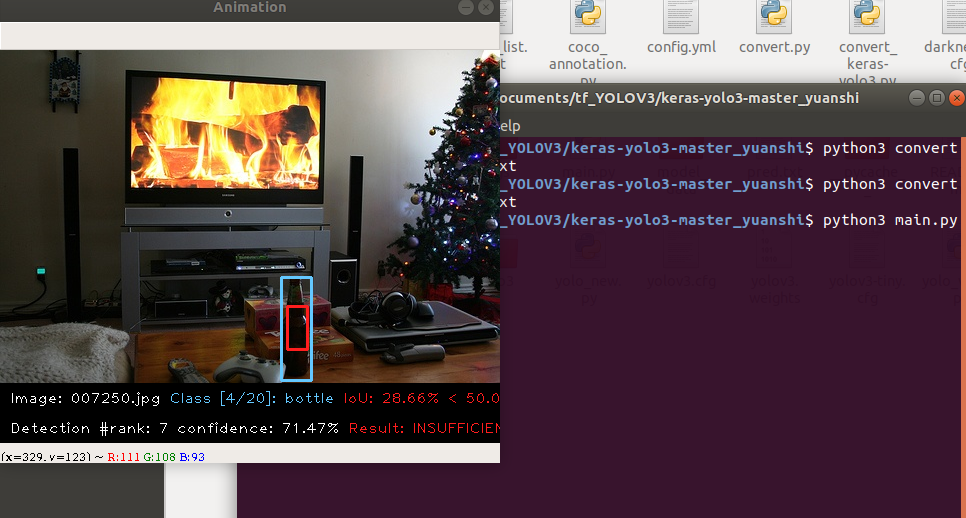
最后会显示每个类别的AP值和mAP值。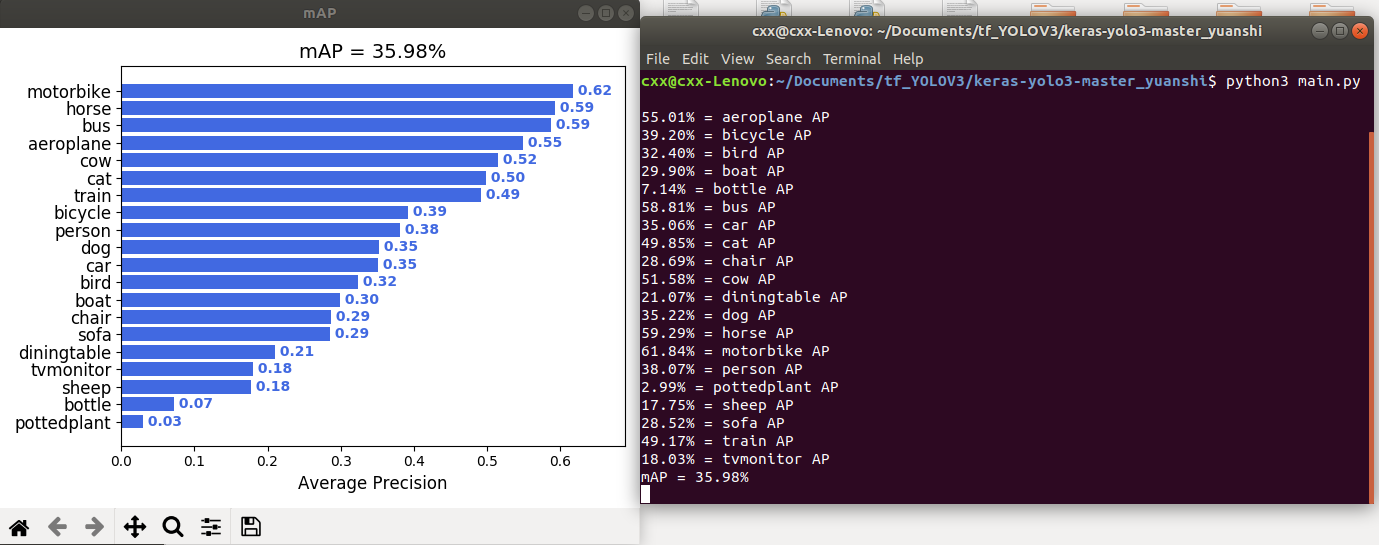
另一种实现YOLO的框架——PyTorch
安装环境
这里详见我的另一篇博客PyTorch的简单使用
快速使用
- 首先从
Github网站上下载PyTorch的源代码:网址。 下载
Yolov3的权重文件:网址,然后将权重放在weights文件夹下。将待检测图片放入到
data/samples文件夹下。运行检测程序
1
python3 detect.py --cfg cfg/yolov3.cfg --weights weights/yolov3.weights
在生成的output文件夹下会看到检测结果: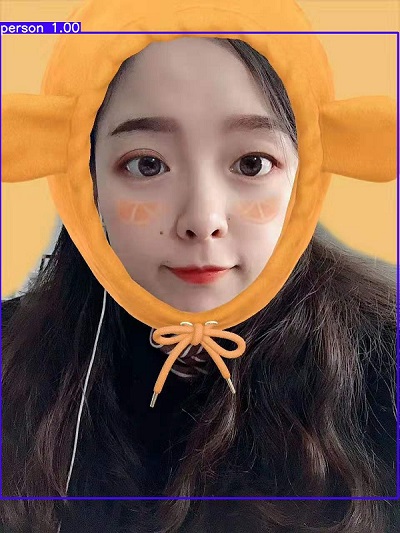
训练自己的数据集
创建数据集
将自己的数据集JPEGImages和标注文件Annotations放到data目录下,并新建文件ImageSets,labels文件夹,复制JPEGImages,重命名images。最终的文件目录格式为:1
2
3
4
5
6data
Annotations
images
ImageSets
JPEGImages
labels
生成train.txt,val.txt和test.txt
首先在最外面的文件夹(yolov3)下创建2个py文件:
create_txt.py:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = 'data/Annotations'
txtsavepath = 'data/ImageSets'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('data/ImageSets/trainval.txt', 'w')
ftest = open('data/ImageSets/test.txt', 'w')
ftrain = open('data/ImageSets/train.txt', 'w')
fval = open('data/ImageSets/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
voc_label.py:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57# -*-coding:utf-8-*-
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets = ['train', 'test', 'val']
classes = ["stick"]
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('data/Annotations/%s.xml' % (image_id), encoding='utf-8')
out_file = open('data/labels/%s.txt' % (image_id), 'w', encoding='utf-8')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
print(wd)
for image_set in sets:
if not os.path.exists('data/labels/'):
os.makedirs('data/labels/')
image_ids = open('data/ImageSets/%s.txt' % (image_set), encoding='utf-8').read().strip().split()
list_file = open('data/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write('data/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
voc_label.py中的classes列表改为自己的类别。
运行完create_txt.py后,会在ImageSets文件夹中生成几个txt,里面存放的数据集的名字。运行完voc_label.py后,会在data文件夹中生成所需要的train.txt,test.txt,val.txt,这里存放的都是数据集的路径。
修改配置文件
这里一共需要修改3个配置文件信息,首先是data文件夹里面的coco.names和coco.data。打开coco.names,然后输入自己的类别即可。然后打开coco.data,更改里面的配置信息: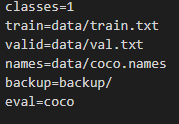
然后打开cfg文件夹下,选择想要训练的模型,并更改相应的参数,可以参照上文的darknet框架部分。
附:配置文件解析
训练
训练之前需要先下载预训练权重,并将其放入weights文件夹下,权重下载地址。注:tiny版本的权重为yolov3-tiny.conv.15。或百度云链接,提取码:jvwg。
然后切换至主文件夹目录下,运行命令即可:1
python train.py --data data/coco.data --cfg cfg/yolov3-tiny.cfg
注:最近的官网源代码对train.py进行了更新,增加了权重文件的参数设置,所以运行命令更改为:1
python train.py --data data/coco.data --cfg cfg/yolov3-tiny.cfg --weights weights/yolov3-tiny.conv.15
注:Ubuntu系统下可能为python3。
训练过程如图所示:
预测
训练结束后,会在weights文件夹下生成很多权重文件,其中best.pt就是最好的权重。首先将需要检测的图片放到data文件夹下的samples文件夹下,然后切换至主文件夹下,运行以下命令:1
python detect.py --data data/coco.data --cfg cfg/yolov3-tiny.cfg --weights weights/best.pt
注:最近的官网源代码对detect.py进行了更新,将data参数设置改为了names参数设置,所以运行命令更改为:1
python detect.py --names data/coco.names --cfg cfg/yolov3-tiny.cfg --weights weights/best.pt
运行结束后,会在主文件夹下生成output文件夹,里面存放着预测结果。
结果分析
训练结束后,除了生成权重文件外,还生成了results.txt文本文件,该文件记录了刚才训练过程中的日志信息,只需执行一条简单的命令就可以将其可视化。1
python -c from utils import utils;utils.plot_results()
运行结束后,会在主文件夹下生成一个result.png。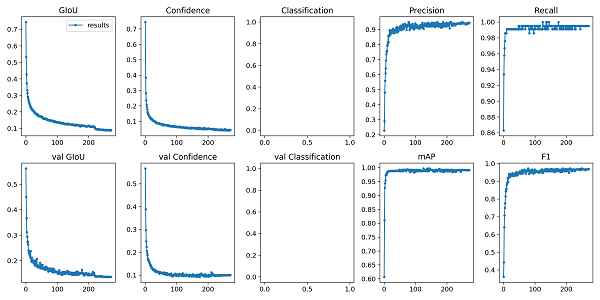
注:不知道为啥Classification没有显示…