概述
2017年1月,Facebook人工智能研究院(FAIR)团队在GitHub上开源了PyTorch,并迅速占领GitHub热度榜榜首。
本博客为我的Github上的项目的使用说明。该项目主要是利用PyTorch深度学习框架进行简单的目标分类。
安装
方法一——官网
登陆PyTorch的官网,在下面找到相应的版本,执行命令即可(windows的安装命令可能是pip):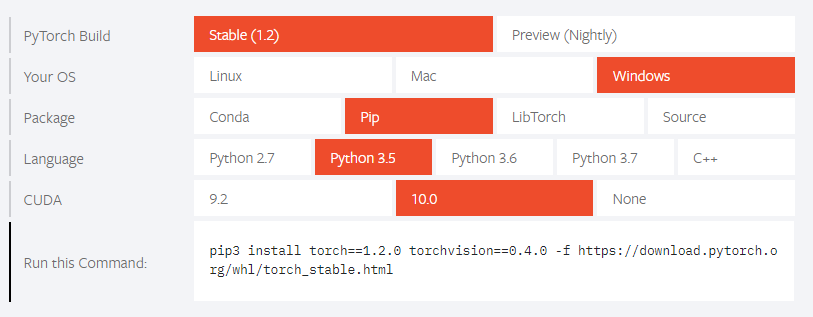
但实际测试发现,这种方式下载的很慢,我们可以用浏览器打开后面的网站,然后在网站中找到需要的版本,在点击下载即可。(可以用IDM下载器)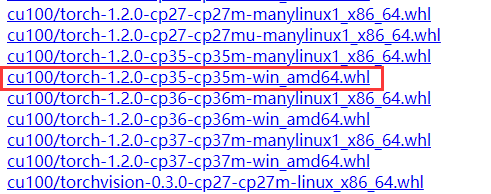
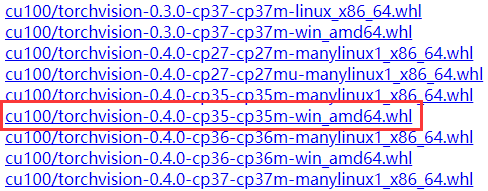
然后使用命令pip install .\torch-1.2.0-cp35-cp35m-win_amd64.whl和pip install .\torchvision-0.4.0-cp35-cp35m-win_amd64.whl即可。
方法二——Anacoda+清华源
这个也是大部分人的安装方法,网上有很多博客介绍,读者可以自行百度学习。
数据集
对于目标分类的数据集,其文件夹目录如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13dataSet
train
1
2
3
valid
1
2
3
test
1
2
3
首先新建3个文件夹,即train,valid和test。然后再分别新建类别文件夹,这里的1,2,3指的是3个类别,最后将图片按类别放入各自的文件夹中。
读取数据集
load_data.py1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16# -*-coding:utf-8-*-
import torch
import torchvision
from torchvision import datasets, transforms
import os
import os.path
def load_data(data_dir, image_size, batch_size):
data_transform = transforms.Compose([transforms.Resize([image_size, image_size]), transforms.ToTensor()])
image_datasets = datasets.ImageFolder(root=os.path.join(data_dir), transform=data_transform)
dataloader = torch.utils.data.DataLoader(dataset=image_datasets, batch_size=batch_size, shuffle=True)
return dataloader
PyTorch常用的读取图片数据集的函数为ImageFolder(),但使用该函数前必须保证图片已经按照刚才的文件夹形式存放好。
该函数的函数声明如下:1
ImageFolder(root,transform=None,target_transform=None,loader=default_loader)
其中,root是在指定的root路径下面寻找图片,transform是对PIL Image图片进行转换操作,target_transform是对label进行变换,loader是指定加载图片的函数,默认操作是读取PIL image对象。
这里我们需要对原始数据集进行简单的处理,即统一大小并转换为Tensor变量。也就是transforms.Resize()和transforms.ToTensor()两个函数。transforms.Compose()指的是将多个操作合并在一起。(当然这里也可以增加其他的图片处理函数)
最后我们用DataLoader()读取数据集。其函数声明为:1
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0)
其中dataset是传入的数据集,batch_size是每个batch有多少个样本,shuffle是在每个epoch开始的时候,对数据进行重新排序,sampler是自定义从数据集中取样本的策略,如果指定这个参数,那么shuffle必须为False,batch_sampler与sampler类似,但是一次只返回一个batch的indices(索引),num_workers这个参数决定了有几个进程来处理data loading。0意味着所有的数据都会被load进主进程。(默认为0)
这里的dataset就是之前ImageFolder()的返回值,这里我们选择shuffle为True,其他除了batch_size均为默认值。
dataloader本质是一个可迭代对象,使用iter()访问,不能使用next()访问;使用iter(dataloader)返回的是一个迭代器,然后可以使用next访问。
我们可以使用下面的测试函数简单看一下数据集。1
2
3
4
5
6
7
8
9if __name__ == "__main__":
data_dir_train = "dataSet/train"
train_data = load_data(data_dir_train, 224, 4)
images, labels = next(iter(train_data))
img = torchvision.utils.make_grid(images)
img = img.numpy().transpose(1, 2, 0)
import matplotlib.pyplot as plt
plt.imshow(img)
plt.show()
显示结果为: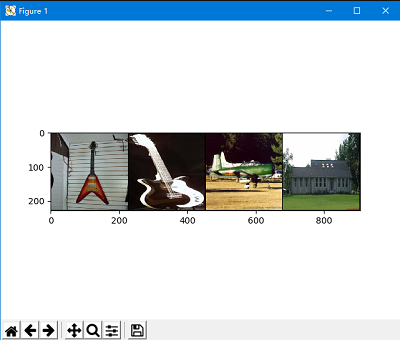
搭建网络模型
model.py1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54# -*-coding:utf-8-*-
import torch
import torch.nn.functional as F
class Models(torch.nn.Module):
def __init__(self, image_dim, n_classes):
super(Models, self).__init__()
self.image_dim = image_dim
self.n_classes = n_classes
self.Conv = torch.nn.Sequential(
torch.nn.Conv2d(in_channels=self.image_dim, out_channels=64, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2),
torch.nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2),
torch.nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2),
torch.nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2),
)
self.Classes = torch.nn.Sequential(
torch.nn.Linear(in_features=14 * 14 * 512, out_features=256),
# 14 * 14 * 512是根据图像的输入和网络结构算出来的
torch.nn.ReLU(),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(in_features=256, out_features=self.n_classes)
)
def forward(self, input):
x = self.Conv(input)
x = x.view(-1, 14 * 14 * 512)
x = self.Classes(x)
return x
在Pytorch中,搭建模型的常用做法是新建一个类,并继承torch.nn.Module这个类,然后在__init__()方法中定义自己的卷积、池化和全连接层等。这里比较简单,熟悉深度学习CNN网络结构的都能看懂。唯一和其他框架不同的是,这里的全连接层的第一个参数,需要自己计算,即代码中的self.Classes中的第一个in_features=14 * 14 * 512,这个是根据输入图片的大小,这里为224*224,然后经过一系列网络结构后得到的输出Tensor后的大小。读者有兴趣可以自己计算一遍,如果更改了图片的大小也需要重新计算。
附:计算公式
训练模型
train.py1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93# -*-coding:utf-8-*-
import torch
from torch.autograd import Variable
from tensorboardX import SummaryWriter
from model import Models
from load_data import *
import yaml
with open("info.yml") as stream:
my_data = yaml.load(stream, Loader=yaml.FullLoader)
# python3.6 可能需要去掉 Loader=yaml.FullLoader
data_dir_train = my_data['data_dir_train']
data_dir_valid = my_data['data_dir_valid']
image_dim = my_data['image_dim']
n_classes = my_data['n_classes']
image_size = my_data['image_size']
batch_size = my_data['batch_size']
learning_rate = my_data['learning_rate']
epochs = my_data['epochs']
writer = SummaryWriter()
def my_train():
use_gpu = torch.cuda.is_available()
dataloader = {"train": load_data(data_dir_train, image_size, batch_size),
"valid": load_data(data_dir_valid, image_size, batch_size)}
model = Models(image_dim, n_classes)
loss_f = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
if use_gpu:
model = model.cuda()
for epoch in range(epochs):
print("Epoch {}/{}".format(epoch + 1, epochs))
print("-" * 10)
running_loss = 0.0
train_correct = 0
train_total = 0
for i, data in enumerate(dataloader["train"], 0):
inputs, train_labels = data
if use_gpu:
inputs, labels = Variable(inputs.cuda()), Variable(train_labels.cuda())
else:
inputs, labels = Variable(inputs), Variable(train_labels)
optimizer.zero_grad()
outputs = model(inputs)
_, train_predicted = torch.max(outputs.data, 1)
train_correct += (train_predicted == labels.data).sum()
loss = loss_f(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
train_total += train_labels.size(0)
print('train %d epoch loss: %.3f acc: %.3f ' % (epoch + 1, running_loss / train_total, 100 * train_correct / train_total))
writer.add_scalar('Train/Loss', running_loss / train_total, epoch + 1)
writer.add_scalar('Train/Acc', 100 * train_correct / train_total, epoch + 1)
# 模型测试
correct = 0
test_loss = 0.0
test_total = 0
test_total = 0
model.eval()
for data in dataloader["valid"]:
images, labels = data
if use_gpu:
images, labels = Variable(images.cuda()), Variable(labels.cuda())
else:
images, labels = Variable(images), Variable(labels)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
loss = loss_f(outputs, labels)
test_loss += loss.item()
test_total += labels.size(0)
correct += (predicted == labels.data).sum()
print('test %d epoch loss: %.3f acc: %.3f ' % (epoch + 1, test_loss / test_total, 100 * correct / test_total))
writer.add_scalar('Test/Loss', test_loss / test_total, epoch + 1)
writer.add_scalar('Test/Acc', 100 * correct / test_total, epoch + 1)
writer.close()
torch.save(model, 'model.pt')
if __name__ == "__main__":
my_train()
首先从配置文件中导入一些必要的参数信息。在正式训练前,可以先检查一下是否装了GPU加速,即torch.cuda.is_available()。为了更好的显示效果,可以安装tensorboardX图形化显示工具。先定义一个writer,即writer = SummaryWriter()。下面正式进入训练。
训练分为训练集和测试集,并分别计算其正确率和Loss值。然后打印每次迭代的相应信息,并将正确率和Loss写入tensorboardX的scalar中,最后关闭writer并保存模型。
训练过程: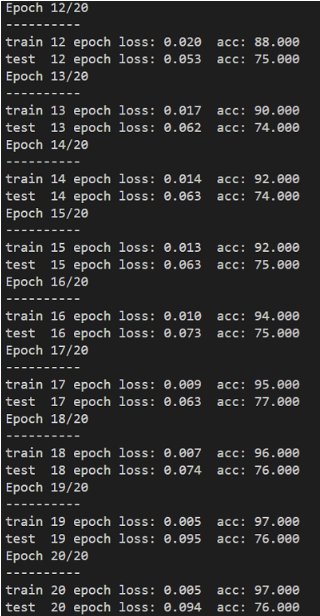
训练结束后,会在文件夹内生成model.pt文件和runs文件夹。其中model.pt就是模型文件,runs文件夹下会有一个以时间命名的文件夹,里面存放的就是tensorboardX生成的日志文件。cd到日志文件的上一层文件夹下,并输入tensorboard查看指令:tensorboard --logdir=***(***就是日志文件的上一层文件夹,不需要引号)。然后将生成的网址放入浏览器中就可以看到可视化的结果了(可能需要IE浏览器)。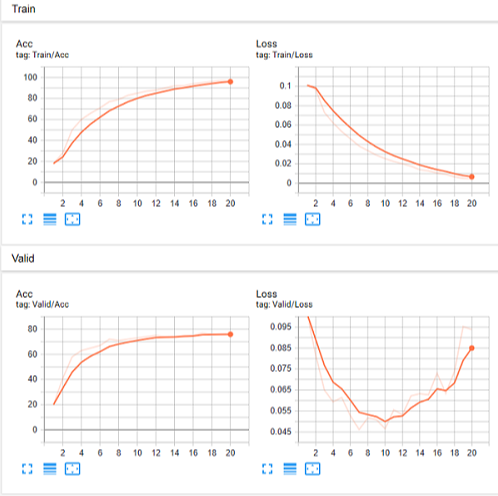
预测
predict.py1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49import torch
from torch.autograd import Variable
from model import Models
from load_data import *
import matplotlib.pyplot as plt
import yaml
with open("info.yml") as stream:
my_data = yaml.load(stream, Loader=yaml.FullLoader)
data_dir_test = my_data['data_dir_test']
data_dir_valid = my_data['data_dir_valid']
image_dim = my_data['image_dim']
n_classes = my_data['n_classes']
image_size = my_data['image_size']
batch_size = 4
def my_predict():
use_gpu = torch.cuda.is_available()
test_data = load_data(data_dir_test, image_size=image_size, batch_size=batch_size)
X_test, y_test = next(iter(test_data))
model = torch.load('model.pt')
if use_gpu:
model = model.cuda()
if use_gpu:
images = Variable(X_test.cuda())
else:
images = Variable(X_test)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
print("Predict Label is: ", predicted.data)
print("Real Label is :", y_test.data)
img = torchvision.utils.make_grid(X_test)
img = img.numpy().transpose([1, 2, 0]) # 转成numpy在转置
plt.imshow(img)
plt.show()
if __name__ == "__main__":
my_predict()
首先利用load()函数导入模型,然后再将测试图片放入模型中得到预测结果。并将预测标签和实际标签分别打印出来。如图所示: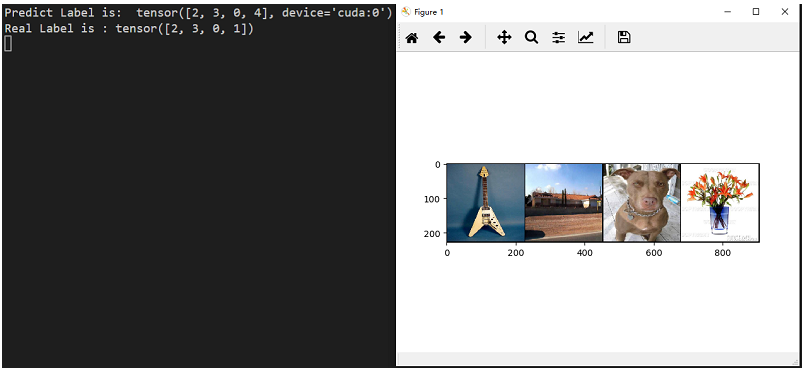
实际测试下来发现,检测效果还是不错的,只有个别几个会判断错误。