概述
之前初级版的视觉系统设计只是通过opnecv简单处理了NAO获得的图像,然后再加上一些判断条件(主要是颜色条件),最后如果满足条件则认为是该目标。虽然总体上可以实现目标的识别,但很容易受到现场环境的影响,不是特别稳定。
在高级版的设计中,我们采用了机器学习中的分类算法。首先根据opencv中的检测算法得到候选区域,然后通过对候选区域的特征提取获得其特征向量,最后通过这些特征向量离线训练分类器模型,从而得到一个较好的分类器。而且该方法适用于任何目标的检测。
候选区域
候选区域的提取是传统图像处理的第一步,能否正确提取到候选区域直接决定着能否检测到目标,现在的机器学习分类算法在分类结果上基本上都能达到很好效果,正确率也能满足要求,但往往在特征区域的提取上会出现偏差甚至检测不到。所以特征提取这一步至关重要。
下面创建一个通用的目标检测类TargetDetection,想用什么方法获得候选区域,就在类中封装成一个方法即可,最后统一返回候选区域(矩形)的左上角和右下角坐标,以便后续的处理。
预处理
之前初级版并没有对原图进行过多的预处理,虽然在比赛时,背景颜色比较单一,不加预处理也可以得到理想的效果,但是为了提高检测的精确度和应用的广泛性,这里稍微加了几个图像处理的方法。
首先介绍几个常见的预处理方法。
灰度化
将彩色图像转化成为灰度图像的过程称为图像的灰度化处理。彩色图像中的每个像素的颜色有R、G、B三个分量决定,而每个分量的取值为[0, 255],每个像素一共有255*255*255种情况。而灰度图像是R、G、B三个分量相同的一种特殊的彩色图像,所以每个像素一共只有255种情况,所以在数字图像处理种一般先将各种格式的图像转变成灰度图像以使后续的图像的计算量变得少一些。
灰度图像的描述与彩色图像一样仍然反映了整幅图像的整体和局部的色度和亮度等级的分布和特征。图像的灰度化处理可用两种方法来实现。
第一种方法是求出每个像素点的R、G、B三个分量的平均值,然后将这个平均值赋予给这个像素的三个分量。第二种方法是根据YUV的颜色空间中,Y的分量的物理意义是点的亮度,由该值反映亮度等级,根据RGB和YUV颜色空间的变化关系可建立亮度Y与R、G、B三个颜色分量的对应:Y=0.3R+0.59G+0.11B,以这个亮度值表达图像的灰度值。(一般采用第二种方法。)
opencv中实现:cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)二值化
将图像上点的灰度置为0或255的过程称为二值化处理,也就是将整个图像呈现出明显的黑白效果(非黑即白)。
所有灰度大于或等于阀值的像素被判定为属于特定物体,其灰度值为255表示,否则这些像素点被排除在物体区域以外,灰度值为0,表示背景或者例外的物体区域。
opencv中实现:cv2.threshold(src, threshold, maxValue, method)图像滤波
图像滤波,即在尽量保留图像细节特征的条件下对目标图像的噪声进行抑制,是图像预处理中不可缺少的操作,其处理效果的好坏将直接影响到后续图像处理和分析的有效性和可靠性。
高斯滤波是一种线性平滑滤波,可以消除高斯噪声。每一个像素点的值,都由其本身和领域内的其他像素值经过加权平均(高斯函数)后得到。
opencv中实现:cv2.GaussianBlur(img, ksize, sigmaX)
HSV空间的二值化
预处理的主要思想是,先将颜色通道转换为HSV空间,当然也可以转到其他的颜色空间,只是实际测试下来发现,HSV空间更加稳定,适合比赛的环境。其次根据HSV空间颜色分布表,设置相应的阈值,将符合的颜色区间二值化,得到一个只有目标区域的图像分布,最后加上几个简单的滤波算法去除噪声。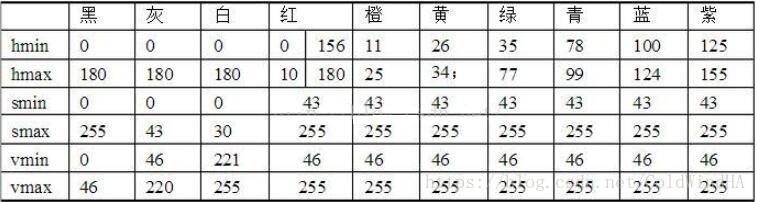
上表为HSV颜色空间表,即每个颜色对应的三个通道的范围。HSV即色相(Hue)、饱和度(Saturation)和明度(Value)。根据其范围,我们就可以将我们需要的颜色提取出来,并二值化处理。
1 | # coding: utf-8 |
首先利用cvtColor()将其转换为HSV空间,然后由表可知目标的颜色范围,从而得到其上限和下限(红色有2个区间),最后利用inRange()将其二值化。inRange():将在两个阈值内的像素值设置为白色(255),而不在阈值区间内的像素值设置为黑色(0)。 最后加个几个简单的滤波处理算法。这里给出了红球的二值化代码,足球和黄杆的代码读者可以先自行考虑。
1 | if __name__ == '__main__': |
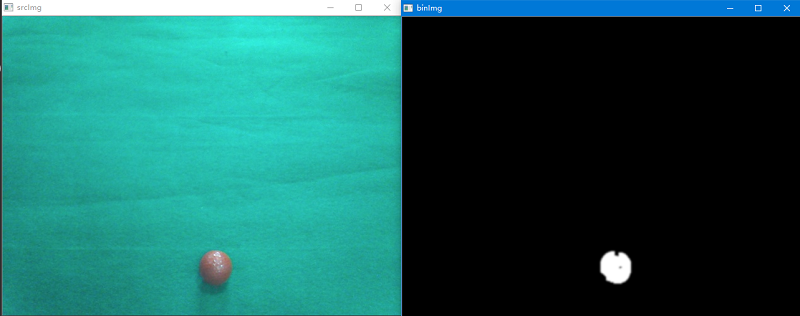
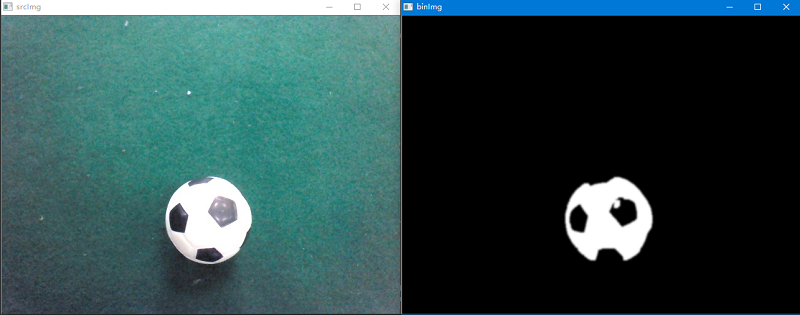
为了克服比赛时场地和光线的干扰,这里的阈值参数可以通过滑动条函数来获得。
1 | def sliderObjectHSV(self, object): |
将其HSV空间的临界值设置为滑动条参数即可。现场调试时,根据实际情况选择一个最优的参数。这里同样只给出红球的代码实例。
霍夫圆检测
针对NAO比赛中的红球和足球,我们可以采用opencv中的霍夫圆检测技术将其检测出来。其函数声明为:HoughCircles(img, method, dp, minDist, param1=100, param2=100, minRadius=0, maxRadius=0),其中method一般为霍夫梯度法,即cv2.cv.CV_HOUGH_GRADIENT,dp=1, param1=100, param2=20,比较重要的参数是圆之间的距离minDist,圆的最小和最大半径minRadius和maxRadius。
1 | class HoughDetection(TargetDetection): |
在调用霍夫圆检测时,首先要将图片进行预处理。这里将比较重要的3个参数作为函数的参数,以便后续的红球和足球的处理。circle2Rect函数的作用是将圆的信息转换为矩阵的信息,并提供一个比例的参数接口,以便后续的矩形区域的调整,showHoughResult函数的作用是在原图中画出圆和矩阵。
下面进行简单的测试,首选读取一张带有红球/足球的图片,然后创建对象并调用预处理方法和霍夫圆检测方法,并将isShow的参数设置为True将其结果显示出来。
1 | if __name__ == '__main__': |
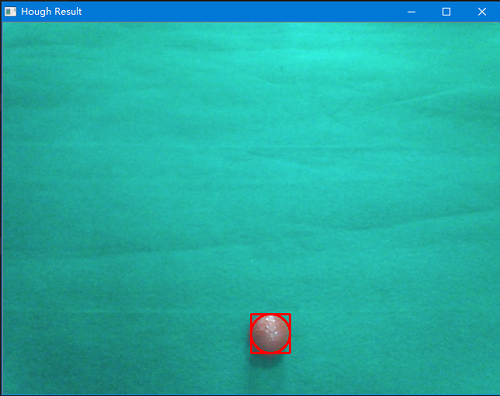
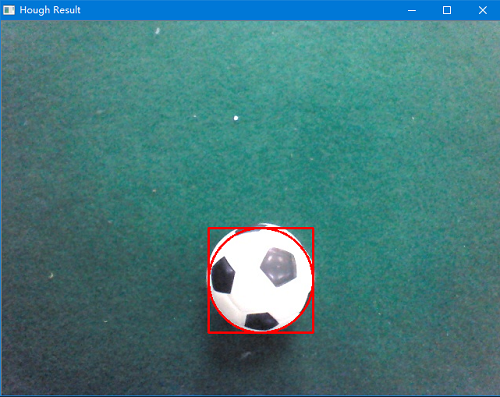
实际测试发现,经过二值化处理后再用霍夫圆检测的效果要比之前直接霍夫圆检测好很多,基本上每次都能选中目标区域。
注:实际测试发现,足球用霍夫圆检测效果并不是太好,轮廓检测(见下文分析)对于足球效果更好。可能因为红球是纯色,二值化后圆的特征比较明显,而足球呈黑白色,圆的特征不是太明显。
轮廓检测
而对于NAO比赛中的黄杆,我们可以采用opencv中的轮廓检测算法。其函数声明为:cv2.findContours(image, mode, method[, contours[, hierarchy[, offset ]]]),其中mode表示轮廓的检索模式,这里选择cv2.RETR_EXTERNAL,即只检测外轮廓,method表示轮廓的近似办法,这里选择cv2.CHAIN_APPROX_NONE,即存储所有的轮廓点。其返回值有2个,contours和hierarchy,分别表示轮廓本身和每条轮廓对应的属性。
1 | class ContoursDetection(TargetDetection): |
该轮廓算法是将所有的轮廓都检测出来,但其中有些结果并不是我们所需要的,所以我们可以采用一些简单的判断条件进行筛选,比如轮廓的周长和轮廓矩形的长宽比等,并将其作为函数的参数以便实际比赛时候的调整。contour2Rect函数的作用是将轮廓的信息转换为矩阵的信息,showContourResult函数的作用是在原图中画出轮廓和矩阵。
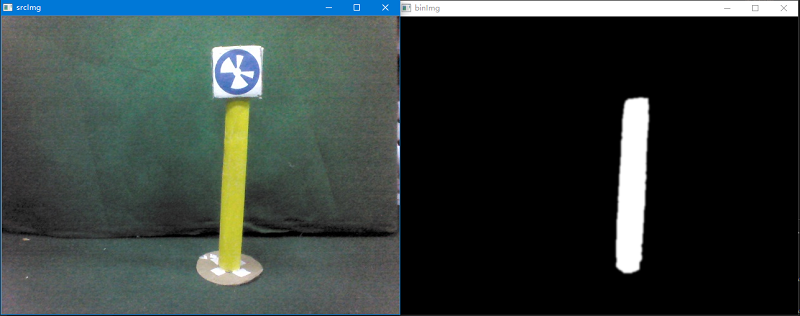
下面进行简单的测试,首选读取一张带有黄杆的图片,然后创建对象并调用预处理方法和轮廓检测方法,并将isShow的参数设置为True将其结果显示出来。
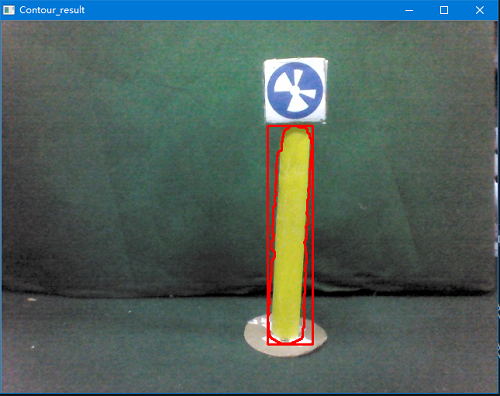
特征提取
检测到目标后,下面就要对其进行特征的提取,从而获得分类器的输入向量。和之前候选区域的提取一样,将所有的特征提取方法封装成一个类,并统一返回向量(列表)的形式。
球类目标颜色特征
首先对于足球和红球最容易想到的就是其颜色特征,之前初级版的设计只是简单的判断颜色所占比例,这并不是一个非常好的标准,因为受到光线等其他因素的影响,在图像中实际的颜色并非我们想象的那样,所以我们采用另一种判断标准。
将每个通道的颜色区间分为若干份,即将[0, 255]区间分成若干个子区间,一般取16比较适中,然后分别统计每个通道的每个像素点属于哪一个子区间,最后统计每个子区间有多少个像素点。例如,R通道的第1个像素点的值为46,属于[32, 47]这个区间,则该区间就+1。这样一共有3*16=48个特征向量,3表示3个通道,16表示16个区间,当然也可以取其他值。
1 | class ColorFeature(object): |
首先通过opencv中的split()方法将图像分成3个通道,然后对每个通道进行颜色特征提取。Channel是一个列表,包含了该通道的每个像素点的值,将其除以总区间个数就可以知道属于第几个区间。例如刚才的像素值46,因为46/16=2,所以属于第2个区间(区间从0开始计),也就是[32, 47]这个区间,即之前的像素点46转换为现在的区间类别2。然后在利用numpy中的bincount()统计方法计算每个区间有多少个像素,注意这里最好在Channel中添加一个元素15,因为图像中不一定存在第16个区间内的像素值,如果不存在,则特征向量的个数就会不同,影响后续的分类器训练,最后在除以总像素个数得到归一化的结果并保留4位小数。
注:python3中需要用//。1
2
3
4
5if __name__ == "__main__":
img = cv2.imread("./img_3/1.jpg")
colorFeature = ColorFeature(img)
colorVector = colorFeature.colorExtract(img)
print(len(colorVector), colorVector)
输出结果为:1
(48, [0.0158, 0.0035, 0.0037, 0.0083, 0.0254, 0.1115, 0.226, 0.2418, 0.1169, 0.065, 0.0429, 0.0272, 0.0223, 0.026, 0.0227, 0.0411, 0.0186, 0.0036, 0.0065, 0.0177, 0.0486, 0.1404, 0.1927, 0.2202, 0.1531, 0.0649, 0.028, 0.0242, 0.0265, 0.0203, 0.0125, 0.0223, 0.0201, 0.0038, 0.0057, 0.0158, 0.0486, 0.1376, 0.1863, 0.2099, 0.172, 0.0964, 0.0419, 0.0261, 0.0145, 0.0107, 0.0067, 0.0039])
HOG特征
HOG特征指的是梯度方向直方图,顾名思义,就是选用梯度方向的分布作为特征。一张图像的梯度(x和y方向的导数)在边缘和拐角(强度变化剧烈的区域)处的梯度幅值很大,而且边缘和拐角比其他平坦的区域包含更多关于物体形状的信息。
首先需要将图像分成小的连通区域,称之为细胞单元。然后采集细胞单元中各像素点的梯度或边缘的方向直方图。最后把这些直方图组合起来就可以构成特征描述器。
这里主要参考了以下两篇博客的:梯度方向直方图,80行Python实现-HOG梯度特征提取。
1 | class HogFeature(): |
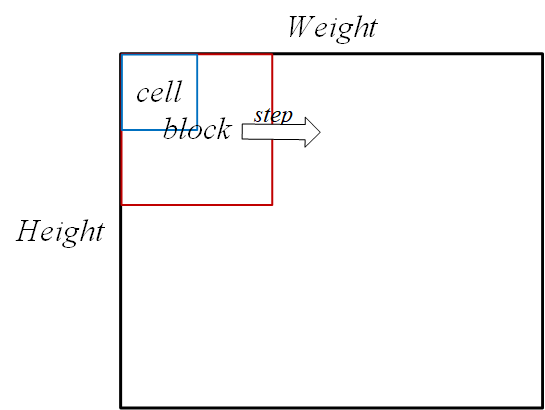
首先在一幅图中选取若干像素组合成一个cell,例如8*8个像素,然后选取2*2个cell,即16*16个像素,组合成一个block。然后将0°-360°划分为若干个区间,比如8个区间,在这8个区间内,统计每个block中的每个cell中的梯度方向直方图(具体见博客),所以一个block有4*8=32个特征向量(因为一个block有4个cell,1个cell有8个直方图特征),然后按照step的大小在图像中移动block,通常step设置为一个cell的大小,即下次移动的时候会和之前的有重复。最后统计一幅图中有多少个block即可算出所有的特征向量个数。例如一个640*480的原始图,其横向有640/8-1=79个block,纵向有480/8-1=59个block,那么其特征向量一个有79*59=4661个,每一个都是一个32维的向量。
1 | if __name__ == "__main__": |
输出结果为(4661, 32)。当然了,这是整幅图的特征向量,实际的特征提取中,只是针对候选区域的(不会太大),所以我们可以将整个候选区域当作一个block,这样特征向量的个数就缩减为32个。
分类器
有了特征向量后,我们就可以选择分类器来训练模型。
Logistic回归
Logistic回归是一个简单的线性二分类的分类算法,其基本原理就是在每个特征上都乘以一个回归系数,然后把所有的结果相加,将这个总和代入到Sigmoid函数中,进而得到一个范围在0~1之间的数值,最后判断当大于0.5的时候就被分为1类,小于0.5就被分为0类。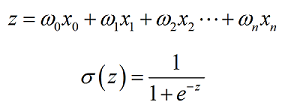
x即输入的特征向量,w即回归系数。下面的问题就是如何找到w的最优解。这里我们采用的优化算法是梯度上升法。其w的更新公式为: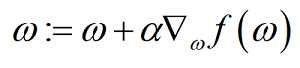
程序实现:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36# coding uft-8
import numpy as np
import math
class Logistic(object):
def __init__(self, filename, maxCycle):
self.filename = filename
self.maxCycle = maxCycle
def loadDateSet(self):
data = np.loadtxt(self.filename)
dataMat = data[:, 0: -1]
classLabels = data[:, -1]
# dataMat = np.insert(dataMat, 0, 1, axis=1)
return dataMat, classLabels
def sigmoid(self, z):
return 1 / (1 + np.exp(-z))
def gradDescent(self, dataMat, classLabels):
dataMatrix = np.mat(dataMat)
labelMat = np.mat(classLabels).transpose()
m, n = np.shape(dataMatrix)
weights = np.ones((n, 1))
alpha = 0.001
for i in range(self.maxCycle):
h = self.sigmoid(dataMatrix * weights)
error = labelMat - h
weights = weights + alpha * dataMatrix.transpose() * error
return np.round(weights, 4)
def classifyVector(self, inX, weights):
prob = self.sigmoid(sum(np.dot(inX, weights)))
return prob
模型训练
有了特征向量和分类器,我们就可以训练模型了。模型中分为正样本和负样本,其训练方法也是不同的。
球类目标
正样本
对于正样本来说,通常的做法是利用数据标注来获得候选区域。常用的数据标注软件有labelImg。该软件不用安装,且使用方法十分简单(自行百度下载)。
打开软件后,首先选择Open Dir打开图像文件夹,然后选择Change Save Dir选择要保存的xml文件的文件路径(标注完成后会生成一个xml文件存放标注信息),然后点击Create RectBox创建矩形,
在需要的区域拖拽鼠标即可,然后在弹出的对话框中选择类别的名称,最后点击save保存,并选择Next Image切换到下一张。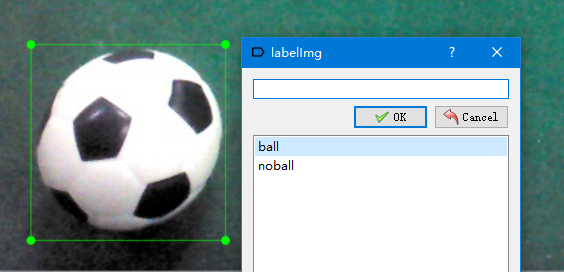
下面就要从生成的xml文件中提取出我们需要的信息。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26<annotation>
<folder>img_2</folder>
<filename>0.jpg</filename>
<path>D:\NAO\visual_cxx\img_2\0.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>640</width>
<height>480</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>ball</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>47</xmin>
<ymin>315</ymin>
<xmax>189</xmax>
<ymax>454</ymax>
</bndbox>
</object>
</annotation>
这是其中的一个xml文件,可以看出我们想要的信息在object项中的第1个和第4个中,即name和bndbox中。利用python内置的ElementTree库就可以解析出我们想要的结果。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20# coding uft-8
import xml.etree.ElementTree as ET
def parseXml(xml_file):
classes_num = {"ball": 1, "noball": 0}
labels = []
tree = ET.parse(xml_file)
root = tree.getroot()
for item in root:
if item.tag == "object":
obj_name = item[0].text
obj_num = classes_num[obj_name]
xmin = int(item[4][0].text)
ymin = int(item[4][1].text)
xmax = int(item[4][2].text)
ymax = int(item[4][3].text)
labels.append([xmin, ymin, xmax, ymax, obj_num])
return labels
返回的labels列表就包括了候选矩形区域的2个顶点坐标及类别。
接下来就是使用之前的特征提取和分类器进行离线训练,在训练之前,我们针对模型进行小小的改进。将整个候选区域分成若干份,比如分成4份,每份都执行同样的特征提取,这样既增加了特征向量的个数,也提高了模型的鲁棒性。
候选区域一般为矩形,所以直接上下等分即可:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20def reshapeBallRect(rawRect, numbers):
n = int(math.sqrt(numbers)) + 1
newPoint = np.zeros((n, n, 2))
newRect = np.zeros((n - 1, n - 1, 4))
initX, initY, endX, endY = rawRect[0], rawRect[1], rawRect[2], rawRect[3] # 初始化参数
# 找出每个小矩阵的顶点坐标
for i in range(n):
for j in range(n):
newPoint[i][j][0] = int(initX + ((endX - initX) / (n - 1) * j))
newPoint[i][j][1] = int(initY + ((endY - initY) / (n - 1) * i))
# 根据坐标构造新矩阵
for i in range(n - 1):
for j in range(n - 1):
newInitX, newInitY = int(newPoint[0 + i][0 + j][0]), int(newPoint[0 + i][0 + j][1])
newEndX, newEndY = int(newPoint[1 + i][1 + j][0]), int(newPoint[1 + i][1 + j][1])
newRect[i][j][0], newRect[i][j][1], newRect[i][j][2], newRect[i][j][3] = newInitX, newInitY, newEndX, newEndY
return newRect
针对球类目标,我们选择颜色和HOG特征提取:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15def calColorFeature(img, number=16):
# 计算颜色特征
color = ColorFeature(img, number)
result = color.colorExtract(img)
return np.round(result, 4)
def calHOGFeature(img, cell_size):
# 计算HOG特征
rectBallArea = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
hog = HogFeature(rectBallArea, cell_size)
vector, image = hog.hog_extract()
return np.round(vector[0], 4)
最后统一保留4位小数。
然后就是采集大量的正样本图片(越多越好,至少上百张),最后将这些特征向量全部合并到一个列表中,并保存到txt文件里,以便后续分类器的处理。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32def calPosVector(writeFilename, labelNumbers):
with open(writeFilename, 'w') as f:
for i in range(labelNumbers):
print('test ' + str(i))
resultTotal = []
xmlFile = "./label_2/" + str(i) + ".xml"
labels = parseXml(xmlFile)
img = cv2.imread("./img_2/" + str(i) + ".jpg")
initX, initY, endX, endY = labels[0][0], labels[0][1], labels[0][2], labels[0][3]
Rect = [initX, initY, endX, endY]
newRects = reshapeHoughRect(Rect, 4)
for newRectRow in newRects:
for newRect in newRectRow:
newInitX, newInitY = int(newRect[0]), int(newRect[1])
newEndX, newEndY = int(newRect[2]), int(newRect[3])
rectBallArea = img[newInitY:newEndY, newInitX:newEndX, :] # 矩形区域(宽,高,通道)
cv2.rectangle(img, (newInitX, newInitY), (newEndX, newEndY), (0, 0, 255), 2) # 画矩形
resultColor = calColorFeature(rectBallArea, 16)
cellSize = min(newEndX - newInitX, newEndY - newInitY)
result_HOG = calHOGFeature(rectBallArea, cellSize / 2)
resultTotal.extend(resultColor)
resultTotal.extend(result_HOG)
print('resultTotal', len(resultTotal))
cv2.imshow("Original", img)
cv2.waitKey(0)
row = ' '.join(list(map(str, resultTotal))) + ' ' + str(labels[0][4]) + '\n'
f.write(row)
首先从标注文件xml中获得lables信息,然后依次打开正样本图片,并根据信息获得其中的候选区域,再对其4等分处理,对每一个等分矩阵进行颜色和HOG特征的提取,注意此时的HOG特征中的block区域为整个等分矩阵区域,所以其cell_size大小的选取应为长宽中的最小值的一半。(cell_size一般为block的一半)。所以单个等分矩阵的HOG特征的特征向量一共有4*8=32个,颜色特征的特征向量个数为16*3=48个,即总的候选区域的特征向量个数为80*4=320个。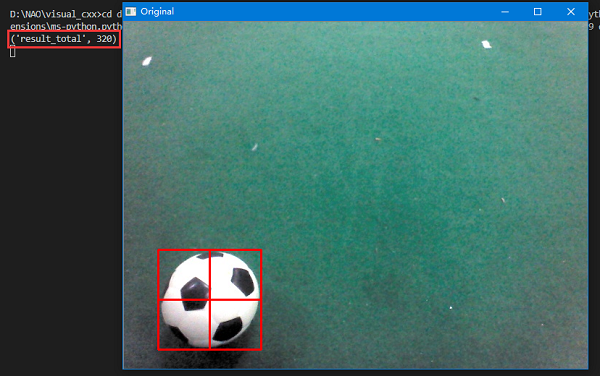
单张图片的实验结果,特征向量太多了,这里就不显示了。
负样本
而对于负样本的训练,就不能采用标注的方法了,而是直接调用之前的霍夫圆检测算法检测原图,当然了,原图不应该包含我们的球类目标,而且二值化的阈值范围要放大一点,以防止检测不出足球/红球。这里我们直接只使用灰度化处理,不进行二值化处理。其算法检测出来多少个圆就当作多少个负样本,最后在对其特征向量的提取并存放在txt文件中,以便后续的分类器训练。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33def calNegVector(writeFilename, labelNumbers):
with open(writeFilename, 'w') as f:
for i in range(labelNumbers):
print('test ' + str(i))
srcImg = cv2.imread("./img_3/" + str(i) + ".jpg")
hogDec = HoughDetection(srcImg)
preImg = cv2.cvtColor(srcImg, cv2.COLOR_BGR2GRAY)
circles = hogDec.houghDetection(preImg, minDist=100, minRadius=25, maxRadius=80)
for circle in circles:
resultTotal = []
rect = hogDec.circle2Rect(circle)
if rect[0] < 0 or rect[1] < 0 or rect[2] > 640 or rect[3] > 480:
continue
newRects = reshapeHoughRect(rect, 4)
for newRectRow in newRects:
for newRect in newRectRow:
newInitX, newInitY = int(newRect[0]), int(newRect[1])
newEndX, newEndY = int(newRect[2]), int(newRect[3])
rectBallArea = srcImg[newInitY:newEndY, newInitX:newEndX, :] # 矩形区域(宽,高,通道)
cv2.rectangle(srcImg, (newInitX, newInitY), (newEndX, newEndY), (0, 0, 255), 2) # 画矩形
resultColor = calColorFeature(rectBallArea, 16)
cellSize = min(newEndX - newInitX, newEndY - newInitY)
result_HOG = calHOGFeature(rectBallArea, cellSize / 2)
resultTotal.extend(resultColor)
resultTotal.extend(result_HOG)
print('resultTotal', len(resultTotal))
cv2.imshow("Original", srcImg)
cv2.waitKey(0)
row = ' '.join(list(map(str, resultTotal))) + ' ' + str(0) + '\n'
f.write(row)
最后一行的label标签需要更改为0。
结果测试
有了正负样本的特征向量后,就可以放入到分类器里面去训练参数了,这里将所有的特征向量都合并到一个txt文件里面。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60def resultTest(method):
trainingSet = []
trainingLabels = []
with open("data.txt", 'r') as f:
for line in f.readlines():
currLine = line.strip().split()
lineArr = []
for i in range(320):
lineArr.append(float(currLine[i]))
trainingSet.append(lineArr)
trainingLabels.append(float(currLine[320]))
if method == "Logistic":
log = Logistic("data.txt", 500)
trainingWeights = log.gradDescent(trainingSet, trainingLabels)
numbers = 39
for i in range(numbers):
print("test" + str(i))
srcImg = cv2.imread("./images/" + str(i) + ".jpg")
conDet = ContoursDetection(srcImg)
preImg = conDet.preProcess(srcImg, "football")
rects = conDet.contoursDetection(preImg, minPerimeter=200, minK=0)
if rects == []:
print("test" + str(i) + " no rects")
for rect in rects:
resultTotal = []
rect = conDet.contour2Rect(rect)
if rect[0] < 0 or rect[1] < 0 or rect[2] > 640 or rect[3] > 480:
print("out of bound")
continue
newRects = reshapeHoughRect(rect, 4)
for newRectRow in newRects:
for newRect in newRectRow:
newInitX, newInitY = int(newRect[0]), int(newRect[1])
newEndX, newEndY = int(newRect[2]), int(newRect[3])
rectBallArea = srcImg[newInitY:newEndY, newInitX:newEndX, :]
resultColor = calColorFeature(rectBallArea, 16)
cellSize = min(newEndX - newInitX, newEndY - newInitY)
resultHOG = calHOGFeature(rectBallArea, cellSize / 2)
resultTotal.extend(resultColor)
resultTotal.extend(resultHOG)
resultTotal = np.array(resultTotal).reshape(1, -1)
classify = log.classifyVector(resultTotal, trainingWeights)
if classify > 0.5:
classifyResult = "yes"
cv2.rectangle(srcImg, (rect[0], rect[1]), (rect[2], rect[3]), (0, 0, 255), 2)
else:
classifyResult = "no"
cv2.rectangle(srcImg, (rect[0], rect[1]), (rect[2], rect[3]), (0, 255, 255), 2)
print('classify', classifyResult)
cv2.imshow("test " + str(i), srcImg)
cv2.waitKey(0)
首先打开特征向量的文本文件,将所有的特征向量和标签分布放到2个列表中,然后放到分类器里面得到权重参数,然后对每一张图片进行目标检测,并获得该目标区域的特征向量,在放到分类器里面得到预测的结果,最后如果概率大于0.5,则认为是,否则为不是。
下图为其中一张的测试结果: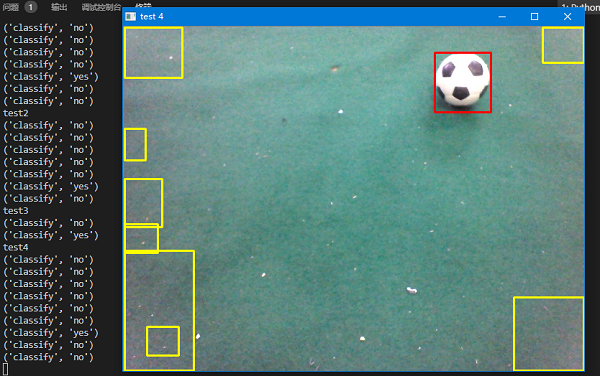
其中红色为正确的目标,黄色为错误的目标。实际测试下来,几乎可以达到实时检测,正确率也达到了比赛的标准。
黄杆类目标
黄杆类目标的模型训练和球类目标基本上一致,重复性的工作这里就不再叙述,读者可以自行考虑代码设计。
这里同样对模型进行一点改进,由于黄杆是细条型的矩形框,所以不能采用之前的均分方法。这里采用一种新的等分方法:首先找到黄杆的矩形框,然后将其左右延申,将landmark标记也框在矩形框内,然后为了克服随机性,将矩形框上下延申至图像的顶部和底部,最后再将其四等分。如图所示:
1
2
3
4
5
6
7
8
9
10
11
12def reshapeStickRect(rawRect, numbers):
newRect = np.zeros((numbers, 4))
initX, initY, endX, endY = rawRect[0], rawRect[1], rawRect[2], rawRect[3] # 初始化参数
# 找出每个小矩阵的顶点坐标
for i in range(numbers):
newRect[i][0] = initX
newRect[i][1] = initY + ((endY - initY) / numbers) * i
newRect[i][2] = endX
newRect[i][3] = initY + ((endY - initY) / numbers) * (i + 1)
return newRect
特征向量的提取和之前的球类目标类似,这样总的特征向量仍然为320个。
总结
高级版的设计其实也就是传统的目标检测方法,一般分为三个阶段:首先在给定的图像上选择一些候选的区域,然后对这些区域提取特征,最后使用训练的分类器进行分类。
随着技术的发展,现在目标检测的普遍做法是利用深度学习来训练模型,得到的分类器更具体一般性,效果也更好。这里就不再过多的叙述了,以后有机会也会发布深度学习版的NAO比赛目标检测。